Observer GigaFlow Documentation
Table of Contents
- Legal
- Glossary
- Introduction
- About GigaFlow
- How-To Guide for GigaFlow
- First Steps
- PostgreSQL 16.1 upgrade (for GigaFlow version 18.19.0.0 thru 18.21.X.X)
- Managed PostgreSQL 16.1 upgrade (for GigaFlow version 18.22.2.0 and newer)
- Conducting Searches in GigaFlow
- Diagnostics and Reporting
- Explore Bandwidth Usage by Interface and Application
- Identify Bandwidth Usage by User
- Use First Packet Response to Understand Application Behaviour
- Determine if Bad Traffic is Affecting Your Network
- Create a Script
- Create a Site
- Create and Use a Profile
- Create an Integration
- Extract a GigaStor trace file
- Respond to a Blacklist Email Alert
- Configuration and System Set-up
- FAQs and Troubleshooting
- Reference Manual for GigaFlow
- GigaFlow Search
- Dashboards
- Enterprise Dashboard
- Server Overview
- Device Overview
- Interface Overview
- Interface Details
- Attributes and Tools
- Summary Interface Total Traffic
- Summary Interface In
- Summary Interface Out
- Summary Interface In Packets
- Summary Interface Out Packets
- Summary Interface In Flows
- Summary Interface Out Flows
- Summary Interface DSCP In Ingress Bytes
- Summary Interface DSCP Out Ingress Bytes
- Summary Interface DSCP In Egress Bytes
- Summary Interface DSCP Out Egress Bytes
- Application Overview
- Source IP Overview
- Destination IP Overview
- Sites Overview
- Top Sites Sources (Last Hour v Last Week Hour)
- Top Sites Destinations (Last Hour v Last Week Hour)
- Top Sites Sources (Last Hour v Week Last Week Hour)
- Top Sites Destinations (Last Hour v Week Last Week Hour)
- Summary Source Sites
- Summary Destination Sites
- Events
- My Current Queries
- My Complete Queries
- All Complete Queries
- All Current Forensics
- Canceled Queries
- Cluster Search
- DB Queries
- Forensics
- First Packet Response
- Ip Viewer
- NAT Reporting
- Network Audits
- Saved Reports
- Server Discovery
- Server Discovery/Detailed Information
- System Wide Reports
- SQL Reports
- Trace Extraction Jobs
- User Events
- Applications
- Existing Defined Service
- Existing Defined Application
- Existing Flow Objects
- Existing Protocol/Port Applications
- Attributes
- Cloud Services
- GEOIP
- Infrastructure Devices
- Detailed Device Information
- SNMP Settings
- SNMP Information Gathered
- Device SNMP Issues
- Attributes and Tools
- Storage Setting
- Other Settings
- Profiling
- Reporting
- New Report Link
- Import Report Link
- General
- Forensics Reports
- Existing DSCP Names
- New DSCP Name
- Existing Report Links
- Server Subnets
- Sites
- Alerting
- Event Scripts
- GigaFlow Cluster
- This Server
- New Cluster Server
- Cluster Access
- Search the GigaFlow Cluster
- Encryption and GigaFlow Clusters
- Global
- General
- LDAP
- SSL
- Remote Services
- SNMP V2 Settings
- SNMP V3 Settings
- Log Setting
- Proxy Setting
- MAC Vendors
- Mail Settings
- Storage
- Data Retention and Rollup
- Integrations
- GigaStor
- Import/Export
- Licenses
- GigaFlow License
- 3rd Party Licenses
- Cleartext Communication
- Call Home Send
- Call Home Response
- Call Home Errors
- License
- Receivers
- Syslog Parsers
- System Health
- System Status
- Users
- Existing Users
- Add Local User
- Add User Group
- Existing User Groups
- Existing LDAP Groups
- Add LDAP User
- Add LDAP Group
- Existing LDAP Nested Groups
- Existing Portal Users
- Add Portal User
- Existing Data Access Groups
- Add Data Access Group
- Watchlists
- Forensic Report Types
- Application
- ASs by Dst
- ASs by Source
- ASs Pairs
- Address Pairs
- Addresses As Sources And Dest Port By Dest Count (Edit?)
- Addresses By Dest
- Addresses By Source
- All Fields
- All Fields Avg FPR
- All Fields Max FPR
- Application Flows
- Application Flows With User
- Applications With Flow Count
- Class Of Service
- Duration Avg
- Duration Max
- FW Event
- FW Ext Code
- Interface Pairs
- Interface By Dest
- Interfaces By Destination Pct
- Interfaces By Source
- Interfaces By Source Pct
- MAC Address Pairs
- MAC Addresses By Dest
- MAC Addresses By Source
- Ports As Dest By Dest Add Popularity
- Ports As Dest By Src Add Popularity
- Ports As Src By Dest Add Popularity
- Ports As Src By Src Add Popularity
- Ports By Dest
- Ports By Source
- Posture
- Protocols
- Servers As Dest With Ports
- Servers As Dst Address
- Servers AS Src Address
- Servers As Src With Ports
- Sessions
- Sessions Flows
- Sessions With Ints
- Subnet Class A By Dest
- Subnet Class A By Source
- Subnet Class B By Dest
- Subnet Class B By Source
- Subnet Class C By Dest
- Subnet Class C By Source
- Subnet Class C Destination By Dest IP Count
- Subnet Class C Source By Source IP Count
- TCP Flags
- Site By Dest
- Site By Source
- Site Pairs
- URLs
- USers (Report)
- TCP Flags
Observer GigaFlow Documentation
Documentation version 18.24.4.0 was released May 09, 2025.
Legal
Notice
Every effort was made to ensure that the information in this manual was accurate at the time of printing. However, information is subject to change without notice, and VIAVI Solutions reserves the right to provide an addendum to this manual with information not available at the time that this manual was created.
Copyright
© Copyright 2025 VIAVI Solutions. All rights reserved. VIAVI and the VIAVI logo are trademarks of VIAVI Solutions Inc. ("VIAVI"). All other trademarks and registered trademarks are the property of their respective owners. No part of this guide may be reproduced or transmitted, electronically or otherwise, without the written permission of the publisher.
Terms and Conditions
Specifications, terms, and conditions are subject to change without notice. The provision of hardware, services, and/or software are subject to VIAVI standard terms and conditions, available at www.viavisolutions.com/terms. Specifications, terms, and conditions are subject to change without notice. All trademarks and registered trademarks are the property of their respective companies.
Glossary
- AES: the Advanced Encryption Standard, also known by its original name Rijndael, is a specification for the encryption of electronic data established by the U.S. National Institute of Standards and Technology (NIST) in 2001. See Advanced Encryption Standard at Wikipedia for more.
- (An) Application: is an abstract entity within the Application Layer that specifies the shared communications protocols and interface methods used by a particular Flow Object on your network.
- Application Layer: An application layer is an abstraction layer that specifies the shared communications protocols and interface methods used by hosts in a communications network. The application layer abstraction is used in both of the standard models of computer networking: the Internet Protocol Suite (TCP/IP) and the OSI model. Although both models use the same term for their respective highest level layer, the detailed definitions and purposes are different. See application layer at Wikipedia for more.
- Appid: the application ID is a unique identifier for each application. In GigaFlow, Appid is a positive or negative integer value. The way in which the Appid is generated depends on which of the 3 ways the application is defined within the system. Following the hierarchy outlined in Configuration > Profiling -- Apps/Options -- Defined Applications, a negative unique integer value is assigned if (1) the application is associated with a Profile Object or (2) if it is named in the system. If the application is given by its port number only (3), a unique positive integer value is generated that is a function of the lowest port number and the IP protocol.
- ARP: the Address Resolution Protocol is a protocol used by the Internet Protocol (IP) to map IP network addresses to the hardware (MAC) addresses used by a data link protocol. Although a Layer 2 protocol, ARP is used by routers in Layer-3 as opposed to Layer-2 switching, where CAM tables are used. See Address Resolution Protocol.
- Alert: is a GigaFlow record that is created when a monitored flow pattern matches certain criteria. Alerts are usually triggered by unwanted behaviour on the nework. See System > Alerting.
- Allowed: in GigaFlow, an allowed flow pattern is one that will not cause an exception, i.e. trigger an alert. This is used in in GigaFlow's Profiler. See Configuration > Profiling for more.
- Base DN: or Base Distinguished Name. In the LDAP directory, each object has a unique path to its place in the directory. This path is the DN. The base DN is the start part of this LDAP path. See Lightweight Directory Access Protocol at Wikipedia for more.
- Blacklist: this is a list of known malevolent or likely malevolent IP addresses, compiled from online threat lists.
- CAM: a content-addressable memory (CAM) table is the usual implementation of a MAC table, more correctly called a forwarding information base (FIB). A CAM table is a dynamic list of MAC addresses and their corresponding ports. The CAM table is used to enable Layer-2 switching, i.e. direct connections between machines within a LAN at the Layer-2 level. The CAM table is closely associated with the ARP table. See forwarding information base at Wikipedia for more.
- Class of Service (COS): Class of service is a parameter used in data and voice protocols to differentiate the types of payloads contained in the packet being transmitted. See class of service at Wikipedia for more.
- Client: a client is a piece of computer hardware or software that accesses a service made available by a server, in this case GigaFlow. See client (computing) at Wikipedia for more.
- Context (SNMP): SNMP contexts provide VPN users with a secure way of accessing MIB (management information base) data. See Cisco for more.
- Deduplication: In computing, data deduplication is a specialized data compression technique for eliminating duplicate copies of repeating data. See data deduplication at Wikipedia for more.
- Destination IP Address: the destination IP address is the intended receiver of information in a computer-to-computer communication.
- Device: see Infrastructure Device.
- Domain Controller: On Microsoft Servers, a domain controller (DC) is a server computer that responds to security authentication requests (logging in, checking permissions, etc.) within a Windows domain. See domain controller at Wikipedia for more.
- DSCP: or Type of Service. "The type of service (ToS) field in the IPv4 header has had various purposes over the years, and has been defined in different ways by five RFCs. The modern redefinition of the ToS field is a 8-bit differentiated services field (DS field) which consists of a 6-bit Differentiated Services Code Point (DSCP) field and a 2-bit Explicit Congestion Notification (ECN) field". See type of service at Wikipedia for more.
- DNS: the Domain Name System is the naming system used by all devices connected to the Internet. See Domain Name System at Wikipedia for more.
- Entry: an entry flow pattern in GigaFlow is a flow pattern used to define a Profile to be tested against an Allowed profile. This concept is used in GigaFlow's Profiler tool. See Configuration > Profiling for more.
- Exceptions: this is the flow records that have not matched the Allowed Flow record template.
- (GigaFlow) Event: is a GigaFlow record that is created when a monitored flow pattern matches certain criteria. Some things that will trigger an event record include:
- Attempts to access blacklisted resources.
- Profile exceptions, i.e. behaviours deviating from norms.
- A SYN flood event.
- A lost neighbour.
- A new connected device sending flows.
- A connected device that stops sending flows.
See Dashboards > Events for more.
- Flow: a flow is a unique stream of packets in one direction. Cisco standard NetFlow version 5 defines a flow as a unidirectional sequence of packets that all share the following 7 values:
- Ingress interface (SNMP ifIndex).
- Source IP address.
- Destination IP address.
- IP protocol.
- Source port for UDP or TCP, 0 for other protocols.
- Destination port for UDP or TCP, type and code for ICMP, or 0 for other protocols.
- IP Type of Service.
(Taken from Wikipedia.)
GigaFlow supports NSEL, sFlow v5, jFlow, IPFIX, Netflow v5 and Netflow v9.
- Flow Object: this is the abstract grouping of a series of flows that can be called by the profiler. Flow Objects are defined in the Profiler. See Configuration > Profiling for more.
- Flow Posture: if a flow creates a black-list or profile event, an event or alert flow record is created.
- Flow Record Fields in GigaFlow with Java types:
- customerid integer: stores the site source identifier.
- device numeric(39,0): stores the numeric IPV6 address of the device sending us the flow/syslog records.
- engineid integer: stores the site destination identifier.
- srcadd numeric(39,0): stores the numeric IPV6 address of the source for the traffic in this record.
- dstadd numeric(39,0): stores the numeric IPV6 address of the destination for the traffic in this record.
- nexthop numeric(39,0): stores the numeric IPV6 address of the nexthop for the traffic in this record.
- inif integer: SNMP ifIndex of the input interface that seen the traffic for this flow.
- outif integer: SNMP ifIndex of the output interface that seen the traffic for this flow.
- pkts bigint: number of packets transmitted in this flow.
- bytes bigint: number of octets/bytes transmitted in this flow.
- firstseen bigint: millisecond timestamp of when this flow started.
- duration bigint: millisecond duration of this flow.
- srcport integer: source port number for traffic in this flow record.
- dstport integer: destination port number for traffic in this flow record.
- flags integer: TCP flags as an integer value.
- proto integer: IP Protocol number for this flow record.
- tos integer: IP TOS/COS value for this flow record.
- appid integer: assigned application ID; the lowest of src/dst port number.
- srcas integer: source AS number used for this flow.
- dstas integer: destination AS number used for this flow.
- userid text COLLATE pg_catalog."default": user ID for this flow, may be as sent or inferred from other sources.
- userdomain text COLLATE pg_catalog."default": user domain for this flow, may be as sent or inferred from other sources.
- srcmac bigint: source MAC address (Java long value), either as supplied or inferred from other sources.
- dstmac bigint: destination MAC address (Java long value), either as supplied or inferred from other sources.
- postureid integer: marking to indicate this flow is of interest (due to blacklist or profiling problems).
- spare integer: used to store the first packet response value. -1 = unset, -2 = no response in scope.
- url text COLLATE pg_catalog."default": free text field; used for application names or URL data.
- fwextcode integer: additional field used to identify traffic (from Cisco NSEL).
- fwevent integer: additional field used to identify events (from Cisco NSEL).
- FlowSec: see Secflow.
- Hash function: a hash function is any function that can be used to map data of arbitrary size to data of a fixed size. Hash functions are used to uniquely identify secret information, for example user login data. See hash function at Wikipedia for more.
- Hits: in GigaFlow, this is the number of flow records that have matched a particular filter, rule or Allowed profile.
- (SNMP) IfIndex: From Cisco - "One of the most commonly used identifiers in SNMP-based network management applications is the Interface Index (ifIndex) value. IfIndex is a unique identifying number associated with a physical or logical interface. For most software, the ifIndex is the name of the interface".
- Infrastructure Device: is any computing machine connected to your network.
- IP Address: an Internet Protocol address (IP address) is a numerical label assigned to each device connected to a computer network that uses the Internet Protocol for communication. An IP address serves two principal functions: host or network interface identification and location addressing. See IP address at Wikipedia for more.
- LAN: A local area network (LAN) is a computer network that interconnects computers within a limited area such as a residence, school, laboratory, university campus or office building. See local area networkat Wikipedia.
- Layer-2 (L2): in the seven-layer OSI model of computer networking, the data link layer is Layer-2. This layer is the protocol layer that transfers data between adjacent network nodes in a wide area network (WAN) or between nodes on the same local area network (LAN) segment. See network layer at Wikipedia for more.
- Layer-3 (L3): in the seven-layer OSI model of computer networking, the network layer is Layer-3. The network layer is responsible for packet forwarding including routing through intermediate routers. The TCP/IP Internet Layer is a subset of the OSI Network Layer. See network layer at Wikipedia for more.
- LDAP: the Lightweight Directory Access Protocol is an open, vendor-neutral, industry standard application protocol for accessing and maintaining distributed directory information services over an Internet Protocol (IP) network. A common use of LDAP is to provide a central place to store usernames and passwords. This allows many different applications and services to connect to the LDAP server to validate users. See Lightweight Directory Access Protocol Wikipedia for more.
- Lost Neighbour: a monitored IP address that disappears.
- MAC Address: the media access control address of a device is a unique identifier assigned to a network interface controller (NIC) for communications at the data link layer of a network segment. See MAC address> at Wikipedia for more.
- MD5: or Message-Digest-5 algorithm is a hash function designed by Ronald Rivest at MIT. See hash function.
- Nashorn: is a JavaScript engine developed in the Java programming language by Oracle. GigaFlow uses Nashorn to power its JS functionality. See Nashorn (JavaScript engine) at Wikipedia and Oracle Nashorn at Oracle for more.
- Network Address Translation (NAT): is a method of remapping one IP address space into another by modifying network address information in the IP header of packets while they are in transit across a traffic routing device. See Network address translation at Wikipedia for more.
- NetFlow: is a feature that was introduced on Cisco routers around 1996 that provides the ability to collect IP network traffic as it enters or exits an interface. GigaFlow supports NSEL, sFlow v5, jFlow, IPFIX, Netflow v5 and Netflow v9. See also Flow. See NetFlow at Wikipedia for more.
- Poller: A Poller is a collection of devices and template management information base (MIB) variables configured in the LAN management solution (LMS) to monitor the utilization and availability levels of devices that are connected to the network. (Cisco).
- PostgreSQL: GigaFlow uses PostgreSQL for its databasing. See PostgreSQL for more.
- Profile Monitoring: GigaFlow actively monitors flows on your network and matches patterns against flow Profiles created using the Profiler tool. See Configuration > Profiling for more.
- Profiler: GigaFlow allows the creation of an abstract profile. A profile is a flow object that is itself a combination of flow objects. A profile defines an acceptable flow pattern for your network. This concept is used in GigaFlow's Profiler tool. See Configuration > Profiling for more.
- Router: a router is a networking device that forwards data packets between computer networks. A router is primarily a Layer-3 device. See router (computing) at Wikipedia for more.
- Sample Rate (Netflow): some devices, especially older ones, can send sFlow and jFlow in a sampled format. GigaFlow supports sampled data, re-sampling to the correct rate. By default, if the sample rate is contained in the flow record, GigaFlow will use this to resample. If the sample rate is not contained in the flow record, it can be set manually for the device.
To manually set the sample rate for a device, go to Configuration > Infrastructure Devices > Detailed Device Information and Storage Settings.
- Secflow records: a portmanteau of "security" and "flow". Used to denote flow records that indicate a GigaFlow security event.
- SHA: or Secure Hash Algorithm, developed by the NSA. See hash function.
- SIEM: In the field of computer security, security information and event management (SIEM) software products and services combine security information management (SIM) and security event management (SEM). They provide real-time analysis of security alerts generated by applications and network hardware. See Security information and event management at Wikipedia.
- SNMP: Simple Network Management Protocol (SNMP) is an Internet Standard protocol for collecting and organizing information about managed devices on IP networks and for modifying that information to change device behavior. Devices that typically support SNMP include cable modems, routers, switches, servers, workstations, printers, and more. See Simple Network Management Protocol
- Source IP Address: the source IP address is the sender of information in a computer-to-computer communication.
- SQL: Structured Query Language, used to interact with the PostgreSQL database. You can find a complete SQL manual at the PostgreSQL website.
- SYN: to establish a connection, TCP uses a three-way handshake. Before a client attempts to connect with a server, the server must first bind to and listen at a port to open it up for connections: this is called a passive open. Once the passive open is established, a client may initiate an active open. To establish a connection, the three-way (or 3-step) handshake occurs:
- SYN: The active open is performed by the client sending a SYN to the server. The client sets the segment's sequence number to a random value A.
- SYN-ACK: In response, the server replies with a SYN-ACK. The acknowledgment number is set to one more than the received sequence number i.e. A+1, and the sequence number that the server chooses for the packet is another random number, B.
- ACK: Finally, the client sends an ACK back to the server. The sequence number is set to the received acknowledgement value i.e. A+1, and the acknowledgement number is set to one more than the received sequence number i.e. B+1.
At this point, both the client and server have received an acknowledgment of the connection. The steps 1, 2 establish the connection parameter (sequence number) for one direction and it is acknowledged. The steps 2, 3 establish the connection parameter (sequence number) for the other direction and it is acknowledged. With these, a full-duplex communication is established. See Transmission Control Protocol at Wikipedia.
- SYN Flood: a SYN flood is a form of denial-of-service attack in which an attacker sends a succession of SYN requests to a target's system in an attempt to consume enough server resources to make the system unresponsive to legitimate traffic. See SYN flood at Wikipedia.
- Syslog: is a standard for message logging. It allows separation of the software that generates messages, the system that stores them, and the software that reports and analyzes them. Each message is labeled with a facility code, indicating the software type generating the message, and assigned a severity level. See syslog at Wikipedia.
- User: depends on context. The User can be a person authorized to log into your GigaFlow system. See System > Users for more. User can also refer to people authorized to access devices on your network.
- VLAN: or Virtual LAN. "A VLAN is a group of devices on one or more LANs that are configured to communicate as if they were attached to the same wire, when in fact they are located on a number of different LAN segments ... VLANs define broadcast domains in a Layer 2 network". See Understanding and Configuring VLANs at Cisco and Virtual LAN at Wikipedia.
- Watchlists: refers to both blacklists and the opposite, whitelists.
Introduction
This Document
This document consists of two main parts: (i) the Observer GigaFlow How-To Guide and (ii) the Reference Manual for the user interface.
How-To Guide
The How-To Guide contains useful work-throughs for many common GigaFlow tasks.
Reference Manual
This is the official reference manual for the GigaFlow UI, included with every distribution. The Reference Manual provides detailed explanations for each GigaFlow function acccessible through the user interface.
GigaFlow Wiki
The GigaFlow Wiki contains additional detailed material including useful scripts, detailed installation instructions and frequently updated notes. Check here if you have not found what you are looking for in the How-To Guide or the Reference Manual.
About GigaFlow
GigaFlow is Viavi's Netflow collection and monitoring platform. GigaFlow helps you regain control of your IT network, giving you network-based security and application assurance.
From a performance perspective, GigaFlow allows you to:
- Troubleshoot your network using First Packet Response, GigaFlow's network response time tool.
- Audit network applications and infrastucture devices.
- Ensure that application performance is in line with Service level agreements (SLAs).
- Easily monitor network traffic and understand utilization by user and application, i.e. determine where your network traffic is going and who, or what, is using up bandwidth on expensive links.
- Report and filter every session by multiple parameters.
- Integrate with multiple-session reporting technologies.
From a security perspective, GigaFlow allows you to:
- Monitor URLs and network connections.
- Prevent connections to known bad IP addresses.
- Allow known IP addresses.
- Prevent visibility blindspots.
- View logged-in users.
- Ensure that users do not access files or servers outside of set permission levels.
- View connected USB devices.
- Monitor network traffic for unusual patterns using flow profiles that you define, with alerts when exceptions occur, e.g. if a user logs into a machine they have never used before or if traffic is recorded from a never-before-seen machine.
- Identify points of incursion or exfiltration on your network.
- Identify the end users or devices associated with an event.
GigaFlow's benefits include:
- Complete stitched IT forensic evidence.
- No additional network hardware; device management is non-intrusive.
- Threat identification is "always-on".

GigaFlow's core components are:
- Front End
- Apache Velocity Templating Engine: used for all front end page layout.
- JavaScript: provides automatic updating of`the user interface (UI) and polling for new data. Integrates more than 25 open source projects.
- Bootstrap: provides UI components.
- Theme: look and feel provided by out development team's experience.
-
Back End
- Eclipse-Temurin Java 17 (OpenJDK): supported and installed by GigaFlow versions 18.16.0.0 and newer.
- PostgreSQL Database 11 - for versions 18.16.0.0 to 18.18.0.0: required to support partitioning.
- PostgreSQL Database 16.1 - for versions 18.19.0.0 and newer: required to support partitioning.
- JavaScript Engine (Nashorn): required for scripting engine.
GigaFlow supports NSEL, sFlow v5, jFlow, IPFIX, Netflow v5 and Netflow v9.
How-To Guide for GigaFlow
First Steps
Install GigaFlow on a Windows Platform
GigaFlow requires Eclipse-Temurin Java 17 - OpenJDK and PostgreSQL Database 11 (for versions 18.16.0.0 to 18.18.0.0).
GigaFlow requires Eclipse-Temurin Java 17 - OpenJDK and PostgreSQL Database 16.1 (for versions 18.19.0.0 and newer).
The recommended platform for GigaFlow is Windows Server 2016, English Edition. Installation must be performed using a local administrator account, not a domain administrator account.
GigaFlow will install:
- Eclipse-Temurin Java 17 (OpenJDK) - for versions 18.16.0.0 and newer
- PostgreSQL Database 11 - for versions 18.16.0.0 to 18.18.0.0
- PostgreSQL Database 16.1 - for versions 18.19.0.0 and newer
- The Gigaflow Service.
Due to changes in Oracle licensing, VIAVI has replaced Oracle Java in GigaFlow v18.16.0.0. Please note that while this new GigaFlow release no longer uses Oracle Java, the installation procedure will not remove the Oracle Java runtime software since other applications may still depend upon it. If you wish to uninstall Oracle Java, please refer to the instructions found in Removing Oracle Java. |
Legacy GigaFlow versions 18.15.0.0 or older require the use of Oracle Java version 1.8_202 JRE (Java Runtime Environment), which may require a payment of additional license fees to Oracle. If you continue to use these legacy GigaFlow versions, please check directly with Oracle regarding licensing requirements/fees for Oracle Java.
When complete, a new service called GigaFlow will be running and enabled when the server starts up. On running the GigaFlow installer, the installation proceeds as follows:
1. This is the GigaFlow Setup welcome page:

Click Next to continue.
2. On the next page, you can choose whether or not to install start menu shortcuts:

Click Next to continue.
3. The next page displays the GigaFlow End User License Agreement (EULA); you must agree to the terms of the EULA to continue the installation or to use the product.

Click I Agree to continue.
4. On the next page, you are reminded of the system requirements for GigaFlow:

Click OK to continue.
5. After accepting the license agreement and acknowledging the reminder, you can define:
- The ports that GigaFlow will listen on for the product UI.
- How much RAM the product can use. This does not include PostgreSQL requirements.
- The location of the GigaFlow database. The path name must not include spaces.

Click Next to continue.
6. Select a location for the GigaFlow application files. Again, the path name must not include spaces.

Click Install to continue.
7. When the installation is complete, you can click Show Details to see what the installer did.

Click Next to continue.
8. The installation is now finished. With the Run GigaFlow tick box checked, the installer will open the GigaFlow User Interface in your default browser when you click Finish.

9. Your browser will open at the GigaFlow login page. The default credentials are:
- Username: admin
- Password: admin
Below the login panel, you can see your GigaFlow installation version details.

10. After logging in for the first time, the Quick Start Settings page appears. You are prompted here to configure the minimal essential settings for GigaFlow to start working properly:

- Server Name is your name for this server. It does not have to be the same as the server hostname. The Server Name will appear in the web browser title bar.
- Drive to Monitor is the local drive that you want to monitor, for example:
D:/Data. - Minimum Free Space is the minimum free space that you want to maintain on disk before purging old data. This is typically 10% of your total disk space.
- Listener Ports allows you to define a new port, by filling-in the port details and clicking the + icon.
- Existing Listener Ports provides the list of existing listener ports available. Here you can see if these ports are receiving flows or syslogs.
- SNMP V2 Settings and SNMP V3 Settings allow adding SNMP v2 and v3 communities.
Note that you can also see and configure all these settings separately from the System menu, or by clicking the links provided next to each setting name.

If you want to stop seeing the Quick Start Setting page each time you log in, enable the option Do Not Show Quick Start On Startup. This setting is also available from System > Global.
Click Save when finished.
You are ready to use GigaFlow.
See the GigaFlow Wiki for further installation notes.
Log In and Provision GigaFlow
Logging In
Figure: GigaFlow's login screen
Log in to GigaFlow from any browser using your credentials. GigaFlow will open on the Dashboards welcome screen.
See Log in in the Reference Manual.
After logging in for the first time, the Quick Start Settings page appears. You are prompted to configure the minimal essential settings for GigaFlow to start working.
You can also configure the rest of the settings as explained below.
Give the Server a Name
Enter a name for your GigaFlow server. This does not have to be the hostname. This will be used in the title bar and when making calls back to the Viavi home server.
See System > Global in the Reference Manual for more. You can change the server name at any time by navigating to System > Global > General.
Assign the Disk to Monitor
Specify the local drive that you want to monitor, for example: D:/Data.
See also System > Global in the Reference Manual for more. You can change the storage settings at any time by navigating to System > Global > Storage.
Assign Disk Space
Enter how much free space to keep on disk before forensic data is aged out. This is the minimum free space to maintain on your disk before forensic data is overwritten. The default value is 20 GB.
See also System > Global in the Reference Manual for more. You can change the storage settings at any time by navigating to System > Global > Storage.
Define Listener Ports
Add new listener ports, by filling-in the port details and clicking the + icon.
See also System > Receivers in the Reference Manual for more. You can change the storage settings at any time by navigating to System > Receivers.
Enable Call Home Functionality
Enable GigaFlow's call home functionality by configuring the proxy server, if one exists, at System > Global> Proxy. This information is required for several reasons: (i) to allow GigaFlow to call home and register itself; (ii) to let us know that your installation is healthy and working; (iii) to update blacklists. All calls home are in cleartext. See System > Licences for more. The required information is:
- Server ID. This is the unique server ID; it is sent in calls home.
- Proxy address. Leave blank to disable proxy use.
- Proxy port, e.g. 80.
- Proxy user.
- Proxy password.
- Click ? to test the proxy server.
- Click Save
 .
.
See also System > Global in the Reference Manual for more.
Install License
You must enter a valid license key to use GigaFlow. Enter your license key in the text box at the end of the table at System > Licenses. Click ADD to submit.
See also System > Licenses in the Reference Manual.
Enable Blacklists
To begin monitoring events on your network, subscribe to one or more blacklists at System > Watchlists.
See also System > Watchlists in the Reference Manual.
Enable SNMP
To poll your network infrastructure devices, you must provide GigaFlow with SNMP community strings and authentication details. You can do this at System > Global.
SNMP V2 Settings
Enter the community name in the text box and click Save.
SNMP V3 Settings
- Enter a user name.
- Select the Authentication Type. Choose one of the following secure hash functions:
- MD5
- SHA
- HMAC128SHA224
- HMAC192SHA256
- HMAC256SHA384
- HMAC384SHA512.
- Enter an authentication type password.
- Select the Privacy Type. Choose one of the following encryption standards:
- AES-128
- AES-192
- AES-256
- AES-192-3DES
- AES-256-3DES
- DES
- 3DES.
- Enter a privacy password.
- Enter a context. SNMP contexts provide VPN users with a secure way of accessing MIB data. See Cisco and the Glossary for more.
- Click the Save button.
See also System > Global in the Reference Manual.
Enable and Test First Packet Response
First Packet Response (FPR) is a useful diagnostic tool, allowing you to compare the difference between the first packet time-stamp of a request flow and the first packet time-stamp of the corresponding response flow from a server. By comparing the FPR of a transaction with historical data, you can troubleshoot unusual application performance.
To begin using First Packet Response, you must specify the server subnets that you would like to monitor. Navigate to Configuration > Server Subnets.
Select the Server Subnets tab and enter a server subnet of interest. To add a new server subnet:
- Enter the subnet address.
- Enter the subnet mask.
- Click Add Server Subnet.
- Click Cancel to clear the data entered.
By clicking on the Servers tab, you can view a list of the identified servers that will be monitored. You can see a realtime display of the First Packet Response by clicking to enable the ticker beside each server.
By clicking on the Devices tab, you can view a list of infrastructure devices - routers - associated with the server subnets of interest.
Reports for all active monitored servers can be viewed at Reports > First Packet Response.
See also Use First Packet Response to Understand Application Behaviour in the How-to section and Configuration > Server Subnets and Reports > First Packet Response in the Reference Manual for more.
Cleanup for a fresh installation of GigaFlow
If you need to properly uninstall GigaFlow in order to prepare your machine for a fresh installation, then refer to the following procedures depending on your operating system.
Cleanup a Windows machine
Cleanup for a machine with a GigaFlow version before 18.22.X.X
To cleanup your machine, perform the following steps:
- In the GigaFlow installation folder, access the Flow folder.
- Run the uninstall.exe file, and follow the uninstall wizard instructions.
As an alternative, you can also uninstall the NSIS GigaFlow application fromControl Panel\All Control Panel Items\Programs and Features . - There are 2 registry entries which need to be deleted. In the administrator command prompt shell, run the following commands:
-
reg delete "HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\NSIS_AnuViewFlow" /f -
reg delete "HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\AnuViewSoftware" /f
-
To only uninstall PostgreSQL run the uninstall-postgresql.exe file in the |
Cleanup for a machine with GigaFlow version 18.22.X.X and newer
To cleanup your machine, perform the following steps:
- In the GigaFlow installation folder, access the Flow folder.
- Run the uninstall.exe file, and follow the uninstall wizard instructions.
As an alternative, you can also uninstall the NSIS GigaFlow or Observer GigaFlow (if your GigaFlow version is 18.24.0.0 or newer) application fromControl Panel\All Control Panel Items\Programs and Features . - There are 2 registry entries which need to be deleted. In the administrator command prompt shell, run the following commands:
-
reg delete "HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\NSIS_AnuViewFlow" /f -
reg delete "HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\AnuViewSoftware" /f
-
Cleanup a Linux machine
Cleanup for a machine with a GigaFlow version before 18.22.X.X
To cleanup your machine, perform the following steps:
- Open a terminal prompt with suitable permissions.
- To uninstall PostgreSQL, perform the following steps:
- To list the PostgreSQL packages, run the following command:
rpm -qa | grep postgres - For each of the above packages, run the following command:
rpm -e <postgres_package_name>
- To list the PostgreSQL packages, run the following command:
- To uninstall GigaFlow, run the following command:
rm -fr /opt/ros
Cleanup for a machine with GigaFlow version 18.22.X.X and newer
To cleanup your machine, perform the following steps:
- Open a terminal prompt with suitable permissions.
- To uninstall GigaFlow, perform the following steps:
- To list the GigaFlow packages, run the following command:
rpm -qa | gigaflow - For each of the above packages, run the following command:
rpm -e <gigaflow_package_name>
- To list the GigaFlow packages, run the following command:
PostgreSQL 16.1 upgrade (for GigaFlow version 18.19.0.0 thru 18.21.X.X)
Upgrading to PostgreSQL 16.1 on Windows
The following procedure helps you upgrade to a GigaFlow that contains the PostgreSQL 16.1 version.
This procedure assumes the following default locations for PostgreSQL 16.1:
- PostgreSQL 16.1 install folder:
<GF_Install_Dir>\Flow\postgesql16 - PostgreSQL 16.1 data folder:
<GF_Install_Dir>\Flow\postgesql16\data .
If neccesary, then please modify these locations accordingly.
For data migration from PostgreSQL 11 (or a version earlier than PostgreSQL 16.1) to PostgreSQL 16.1, the data folders must reside on the same drive. |
Backup the PostgreSQL data
The upgrade process to PostgreSQL 16.1 requires to migrate the data in the old cluster version to the new major version. This happens outside the GigaFlow installation and to prevent data loss it is highly recommended to backup the original data. The following command will dump the existing PostgreSQL data to an SQL file that is used to restore the data in case of upgrade failures. In the administrator command prompt shell, run the following command:
<GF_Install_Dir>\Flow\postgresql\bin\pg_dump -E UTF8 --host=127.0.0.1 -U myipfix -f <GF_Install_Dir>\GigaFlowBackup.sql
To restore data that was previously saved using the |
Install GigaFlow with PostgreSQL 16.1
- Follow the Windows installation procedure to install GigaFlow: Install GigaFlow on a Windows Platform.
Note:
This will not install the latest PostgreSQL 16.1 version.
Install PostgreSQL version 16.1
- Use the PostgreSQL Windows installer to install PostgreSQL version 16.1.:
<GF_Install_Dir>\Flow\dist\postgresql-16.1-1-windows-x64.exe - Change the install folder to
<GF_Install_Dir>\Flow\postgresql16 . - Change the data folder to
<GF_Install_Dir>\Flow\postgresql16\data .Note:
The data folder for PostgreSQL 16.1 must reside in the same drive as that of the previous PostgreSQL version. - Enter the PostgreSQL password: P0stgr3s_2ME.
- Accept the port 5433 for the new PostgreSQL version 16.1.
- Unmark the Stackbuilder option from the component list.
The old cluster does not need to be deleted. |
If PostgreSQL 11 is used for GigaFlow and other applications, then do not upgrade to PostgreSQL 16.1. This will upgrade the old cluster to the newer version and make it unusable with PostgreSQL 11 version. |
If GigaFlow is set to connect to a remote PostgreSQL installation, then do not upgrade to PostgreSQL 16.1. |
You can ignore the following message: The system cannot find the file specified. |
Let the migration script to run until completion. The completion of this process requires a time period from 10 minutes to several hours, depending on the size of the data that is migrated. When the data migration is successful the message Data migration complete is displayed. |
Data migration to the new PostgreSQL version
- Run the postgres_migration.bat script from the
<GF_Install_Dir>\Flow\resources\docs\sql folder. - On the successful completion of the script, connect to the server and make sure that the data is correct.
Upgrading to PostgreSQL 16.1 on Linux
Server with direct internet access
If the server has internet access, then you can run the following command, which will download the latest build and install it (causing GigaFlow service to restart):
Upgrading to PostgreSQL 16.1
- The upgrade process to PostgreSQL 16.1 requires to migrate the data in the old cluster version to the new major version. This happens outside the GigaFlow installation and to prevent data loss it is highly recommended to backup the original data. The following command will dump
the existing PostgreSQL data to an SQL file that is used to restore the data in case of upgrade failures. In the terminal prompt, run the following command:
pg_dump -E UTF8 --host=127.0.0.1 -U myipfix -f GigaFlowBackup.sql - For GigaFlow 18.19.0.0. and newer, run the following script to upgrade to PostgreSQL 16.1:
/opt/ros/resources/unix/ObserverGigaFlow_Upgrade_PG16.sh 11 Note:
The parameter 11 represents the PostgreSQL version that it upgrades from.
The old cluster does not need to be deleted. |
If PostgreSQL 11 is used for GigaFlow and other applications, then do not run the ObserverGigaFlow_Upgrade_PG16.sh script. This will upgrade the old cluster to the newer version and make it unusable with PostgreSQL 11 version.
|
If GigaFlow is set to connect to a remote PostgreSQL installation, then do not run the ObserverGigaFlow_Upgrade_PG16.sh script.
|
Server without direct internet access
- If the server has no internet access, then copy the build file ObserverGigaFlowUnixx64_rpm.tgz into the server
folder /opt and then run the command:
tar -vxzf /opt/ObserverGigaFlowUnixx64_rpm.tgz -C / - Restart the GigaFlow service.
Upgrading to PostgreSQL 16.1
- The upgrade process to PostgreSQL 16.1 requires to migrate the data in the old cluster version to the new major version. This happens outside the GigaFlow installation and to prevent data loss it is highly recommended to backup the original data. The following command will dump
the existing PostgreSQL data to an SQL file that is used to restore the data in case of upgrade failures. In the terminal prompt, run the following command:
pg_dump -E UTF8 --host=127.0.0.1 -U myipfix -f GigaFlowBackup.sql - For GigaFlow 18.19.0.0. and newer, run the following script to upgrade to PostgreSQL 16.1:
/opt/ros/resources/unix/ObserverGigaFlow_Upgrade_PG16.sh 11 Note:
The parameter 11 represents the PostgreSQL version that it upgrades from.
The old cluster does not need to be deleted. |
If PostgreSQL 11 is used for GigaFlow and other applications, then do not run the ObserverGigaFlow_Upgrade_PG16.sh script. This will upgrade the old cluster to the newer version and make it unusable with PostgreSQL 11 version.
|
If GigaFlow is set to connect to a remote PostgreSQL installation, then do not run the ObserverGigaFlow_Upgrade_PG16.sh script.
|
Managed PostgreSQL 16.1 upgrade (for GigaFlow version 18.22.2.0 and newer)
Starting with GigaFlow version 18.22.2.0 and newer, the GigaFlow installer will no longer include a separate PostgreSQL installer. Instead, the PostgreSQL binaries are now bundled directly within the GigaFlow installer. Specifically, PostgreSQL version 16.1 is included with GigaFlow version 18.22.2.0. The PostgreSQL service operates on the dedicated port 26906 and is registered under the service name GFPostgresSvc. This change simplifies the installation process because it eliminates the need for a separate PostgreSQL installation.
Upgrading from a release prior to GigaFlow version 18.19.0.0
If you are upgrading GigaFlow from a release prior to version 18.19.0.0 that is running a PostgreSQL version less than 16, then the system will be upgraded to PostgreSQL version 16.1. Additionally, your old data will automatically be migrated to this new version.
For details, refer to the Data Migration section.
Upgrading from GigaFlow version 18.19.0.0 release and newer
There are 3 possible upgrade scenarios:
- PostgreSQL version 16.1 was installed with GigaFlow version 18.19.0.0 or newer, and old data was migrated to PostgreSQL version 16.1.
- PostgreSQL version 16.1 was installed with GigaFlow version 18.19.0.0 or newer, but the old data was not migrated to PostgreSQL version 16.1. In this case, PostgreSQL 16.1 was initiated with a new cluster.
- PostgreSQL version 16.1 was not installed. In this case, GigaFlow continues to run with the old PostgreSQL version due to its backward compatibility.
Note:
For this scenario the behavior is the same as upgrading from a GigaFlow version prior to 18.19.0.0. For details, refer to the Data Migration section.Note:
The newly managed PostgreSQL database will not support external applications that use the database. If this is your situation, then proceeding with the installation will delete the databases created by the external applications.
In scenarios 1 and 2, when you install GigaFlow version 18.22.2.0, GigaFlow will be set up with a managed PostgreSQL version 16.1. The existing PostgreSQL service will be deregistered, and a new PostgreSQL service
named
The new PostgreSQL service will utilize the same data folder as the previous one. This entire process will be transparent to the user, ensuring a seamless transition. |
Data Migration
Locally stored PostgreSQL 11 databases will be migrated to PostgreSQL 16.1 automatically. Depending on the size of your database the migration process can take a long time to complete. The newly managed PostgreSQL database will not support external applications using the database. If this is your situation, then migrate your data as needed.
To estimate the size of the database, perform the following steps:
- Login to GigaFlow.
- In the GigaFlow UI, go to the System > Global > Storage tab and note the path from the Data Drive To Monitor field.
- For Windows installations:
- Browse the file system and right-click on the folder from the Data Drive To Monitor path.
- Select the Properties option and note the Size on disk information.
- For Linux installations:
- Login to the system using SSH secure protocol.
- Run the following command:
du -sh /path/to/directory Note:
The part/path/to/directory represents the path found in the Data Drive To Monitor field. - Note the size of the directory.
- For Windows installations:
The duration of the data migration process can be shortened by decreasing the retention period of the forensics data (see Reducing the size of the GigaFlow database prior to installation section).
You must complete this process before installing GigaFlow. |
The following table provides guidance for data migration times on Windows. Your times may vary depending on numerous factors.
| Data Size | Data Migration Time |
|---|---|
| ~6 TB | 10 min |
| ~12 TB | ~2 h |
The following table provides guidance for data migration times on Linux. Your times may vary depending on numerous factors.
| Data Size | Data Migration Time |
|---|---|
| ~5 TB | 3 min |
Reducing the size of the GigaFlow database prior to installation
To reduce the size of the GigaFlow database, perform the following steps:
- Login to GigaFlow.
- In the GigaFlow UI, go to the System > Global > Storage tab.
- In the Max Forensics Storage (Days) field, decrease the number of days for your data to be stored.
Note:
Make sure that the number of days in the Max Forensics Storage (Days) field is larger than the one in the Min Forensics Storage (Days) field. - Click the Save Storage Settings button.
To validate that the storage size is smaller and within acceptable limits, repeat the steps in the Estimating the database size section.
You can restore the number of storage days to their previous configuration after the installation of GigaFlow 18.22.2.0 or newer is complete. |
Windows upgrade
First go to https://update.viavisolutions.com/latest/, download the file ObserverGigaFlowSetupx64.exe and run it.
During the installation of GigaFlow 18.22.2.0 or newer, you will be prompted with different dialogs depending on what version you are upgrading from and different possible scenarios.
If multiple PostgreSQL versions are detected, then GigaFlow will also prompt you with the following screen:

With respect to the scenarios presented in section Upgrading from GigaFlow version 18.19.0.0 release and newer, select the options as follows:
- PostgreSQL 16 option for scenarios 1 and 2
- PostgreSQL 11 option for scenario 3.
Note:
For scenario 3, the setup will install GigaFlow and the managed PostgreSQL version 16.1 followed by an automatic data migration.
Windows data migration
When PostgreSQL 11 option is selected for scenario 3, or you are upgrading from a version prior to GigaFlow 18.19.0.0, the following dialog regarding Data Migration is shown:

If you are concerned about the duration of the data migration process, do not click the Next button. Instead, click the Cancel button to exit the setup and follow the steps in the Estimating the database size section. If this is not your case, then click the Next button to continue the installaion process.
Data migration is monitored every 30 seconds and is displayed in a separate command window. A new logged entry is displayed every 30 seconds until the data migration process is completed. This status window will automatically close at that time.

Logging
Data migration is logged in the file
How to change the PostgreSQL data folder after installation
To change the PostgreSQL data folder on Windows, perform the following steps:
- In Registry Editor, modify the following registry key entry:
HKLM\SYSTEM\CurrentControlSet\Services\postgresql-x64-11\ImagePath
Change the -D option in the value of the key to the new folder, for example:"c:\GigaFlow\Flow\postgresql\bin\pg_ctl.exe" runservice -N "postgresql-x64-11" -D "D:\New_Data_Folder" -w - For GigaFlow version 18.23.0.0 and newer, also modify the following registry key entries to the New_Data_Folder:
HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\AnuViewSoftware\Flow\postgresqlData HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\AnuViewSoftware\Flow\sqlData
Linux upgrade
This procedure is valid for both Oracle Linux 8 and RedHat Enterprise Linux 8.
First go to https://update.viavisolutions.com/latest/ and download the tar file ObserverGigaFlowUnixx64_rpm.tgz.
To untar the file, run the following command:
The tar file contains the following files:
- gigaflow_deps.rpm which contains tools for debugging.
- gigaflow.rpm which contains the GigaFlow binary.
- ObserverGigaFlow_Install.sh that is a wrapper script which helps with the installations.
Clean Install
To install GigaFlow on a new Linux box, run the script using the following command:
This will install the dependencies and the GigaFlow software, and will start the new PostgreSQL version 16.1 service GFPostgresSvc on port 26906.
At the end of the installation output to terminal ignore the following error message:
ERROR: extension "plpgsql" already exists
The default data folder for the managed PostgreSQL on Linux is /opt/ros/pgsql/data. If the default data location needs to be changed, run the following command:
<new_data_folder_path>
The GFPostgresSvc service will start using the new data folder. The default data location will be linked to the new folder, so no other changes are needed.
How to change the PostgreSQL data folder after installation
The default data folder for the managed PostgreSQL on Linux is /opt/ros/pgsql/data. If the default data location needs to be changed, run the following command:
<new_data_folder_path>
The GFPostgresSvc service will start using the new data folder. The default data location will be linked to the new folder, so no other changes are needed.
Upgrade
Before upgrading GigaFlow, make sure that the postgresql service is running.
For upgrades from GigaFlow versions 18.21.0.0 and prior, run the following command:
This will upgrade GigaFlow to the latest version 18.22.2.0. A managed PostgreSQL service GFPostgresSvc is started that will run on port 26906.
If the previous version of PostgreSQL is less than 16 the old data is migrated to the new version. Refer to the Data Migration section for data migration times and steps to reduce the time. The file /tmp/gigaflow/dm.log displays the progress message Data Migration in Progress during the data migration process.
If the previous version of PostgreSQL is already on version 16, then the new GFPostgresSvc service will use the same data folder and with the default data folder /opt/ros/pgsql/data linked to it.
|
Logging
For the logging information of the installation process, refer to the file /tmp/gigaflow/gigaflow.log.
Remote PostgreSQL
If GigaFlow is installed and connected to a PostgreSQL running remotely, then no data migration is performed by the installation process. You need to do the data migration manually.
The installation process will update GigaFlow and start the managed PostgreSQL locally on port 26906.
GigaFlow version 18.22.2.0 will be the last release that supports remote PostgreSQL. |

The same message as above is displayed on the Linux terminal when the ObserverGigaFlow_Install.sh script is run with the upgrade parameter.
Multiple Applications using the GigaFlow PostgreSQL installation
If applications other than GigaFlow have databases in the same PostgreSQL service that is used by GigaFlow, and a data migration is performed, then only the GigaFlow database will be migrated causing the other databases to be deleted. If this is detected, then the following warning shows.

The same message as above is displayed on the Linux terminal when the ObserverGigaFlow_Install.sh script is run with the upgrade parameter. You will have the choice to continue the installation process or to exit.
Troubleshooting a failed PostgreSQL migration
Windows troubleshooting
The Windows installer for GigaFlow 18.22.2.0 which contains the GigaFlow managed PostgreSQL binaries version 16.1 will perform the data migration if the version on the system that is upgraded is prior than 16.1. This is different from the process related to version 18.21.0.0 and prior, where you needed to manually install PostgreSQL 16.1 from a PostgreSQL Windows installer in the dist folder.
PostgreSQL service status
Make sure that the PostgreSQL service is running before you start the installation, since the scripts use the running service to query the data folder and the version.
To do this in Windows, open the services panel and check the state of the service. If the PostgreSQL service is not running or cannot start, then you need to fix this before you begin the installation process.
You can use the Windows Event Log to determine the root cause. The log folder in the PostgreSQL data folder has log files for each day which might contain useful information.
Selecting the correct PostgreSQL version during installation
If the installer detects multiple versions of PostgreSQL in the HKLM\System\CurrentControlSet\Services registry entry, then it will prompt the user to select the one used for GigaFlow.
If the wrong version is selected, then the installer fails with an error message since it will try to initialize PostgreSQL data but the folder is not empty. In this case abort the installation and retry.
Data migration on Windows
The GigaFlow installer will perform the data migration as part of the installation process. If the data migration fails, then refer to the <GigaFlow_InstallDir>\pgdm.log file for the last successful step.
Check if any of the following cases apply to your failure scenario:
- Access to the necessary folders could not be granted for pg_upgrade.
- Open the <GigaFlow_InstallDir>\permission.log file and search for the keyword Failed. Run the following command in Command Prompt:
findstr "Failed processing" <GigaFlow_InstallDir>\permission.log - All the Failed entries should report 0. If this is not the case, then perform the following step:
- Right-click the related folder, select the Properties option and grant permissions manually. The security tab will show if the current user has Full Access to the folder.
- Open the <GigaFlow_InstallDir>\permission.log file and search for the keyword Failed. Run the following command in Command Prompt:
- The pg_upgrade step has the check flag failed.
- For all the errors that occurr during the pg_upgrade refer to the log files found in the pg_upgrade_output.d folder in the data folder of the new cluster. Check the correctness of the folder paths in the file <GigaFlow_InstallDir>\pg_upgrade_params.txt
- The pg_upgrade_internal.log file will contain the reason for the failure.
The most common error is that it cannot create a hard link. This can occur if the data folder for the old and the new clusters are not in the same drive. - The PostgreSQL bin and data directories are read from the following registry entries. If these entries are incorrect, then edit and correct them, and retry the data migration.
HKLM SYSTEM\CurrentControlSet\Services\postgresql-x64-11 "ImagePath"HKLM SYSTEM\CurrentControlSet\Services\postgresql-x64-16 "ImagePath"
Once the issue is resolved you must run the data migration from the Command Prompt in Administrator mode as follows:
<GigaFlow_InstallDir>\resources\docs\sql\startDataMigration.bat <GigaFlow_InstallDir>\pg_upgrade_params.txt After the data migration process is successfully completed, run the following commands:
net start GFPostgresSvc <GigaFlow_InstallDir>\resources\docs\sql\postgresinstall.bat <GigaFlow_InstallDir> sc config GigaFlow depend= "" net start GigaFlow <GigaFlow_InstallDir>\resources\docs\sql\addDependency.bat
- If the pg_upgrade completed successfully but the message Data Migration Complete is not printed on the screen (not very common), then perform the following steps:
- In the new PostgreSQL cluster data folder, open the postgresql.conf file and search for port. If the port is not 26906, then change it to this value.
- Start the GFPostgresSvc service from the services panel.
- Change the postgresql-x64-11 service to manual from the services panel.
- Start the GigaFlow service.
- If the GigaFlow log file reports incorrect password for the user myipfix (not very common), then perform the following steps:
- Stop the GigaFlow service.
- Stop the GFPostgresSvc service.
- In the new PostgreSQL cluster data folder, open the pg_hba.conf file and at the bottom change all scram-sha-256 entries to trust.
- Restart the GFPostgresSvc service.
- Open the Command Prompt window as administrator and run the following command:
C:\GigaFlow\Flow\resources\docs\sql\postgresinstall.bat - Stop the GFPostgresSvc service
- In the data folder, pg_hba.conf file, replace trust with scram-sha-256.
- Restart the GFPostgresSvc service.
- Restart the GigaFlow service.
Linux troubleshooting
If the installation or the data migration process fails, then check the logs in the /tmp/gigaflow folder. The gigaflow.log file contains the installation logs.
If the data migration fails, then refer to the log files from the pg_upgrade_output.d folder present in the /opt/ros/pgsql/data folder.
The /tmp/gigaflow/ folder will have a file named pg_upgrade_check.sh which has the bin and data folder paths of the old and new PostgreSQL. Make sure that the paths are correct.
After the issue is fixed, run the following commands to restrat the data migration process:
su - postgres < /tmp/gigaflow/pg_upgrade_check.sh su - postgres < /tmp/gigaflow/pg_upgrade.sh systemctl start GFPostgresSvc su - postgres < /opt/ros/resources/unix/altermyipfixdb.sh
Conducting Searches in GigaFlow
Search for Security Events Associated with an IP Address
To find out more about a particular IP address:
- Enter an IP address in the main GigaFlow Search box at the top of the screen.
- Click Go.
- Select a reporting period and click Submit .
Click on Events tab in the panel on the left side of the screen.
The infographics and tables display all the security events associated with that IP address during the reporting period.
See Search and Events in the Reference Manual for more.
Conduct a Search and Apply a Macro or Script
See Reports > System Wide Reports > Device Connections and Reports > System Wide Reports > MAC Address Vendors in the Reference Manual to find out get a list of MAC addresses associated with your network.
Search for a MAC Address
See Search in the Reference Manual for more.
Search for a MAC address to see what device it is connected to and the VLAN it is in:
- Enter the entire MAC address into the search box.
- You must enter the full address.
- GigaFlow's MAC address search works for any standard MAC address format.
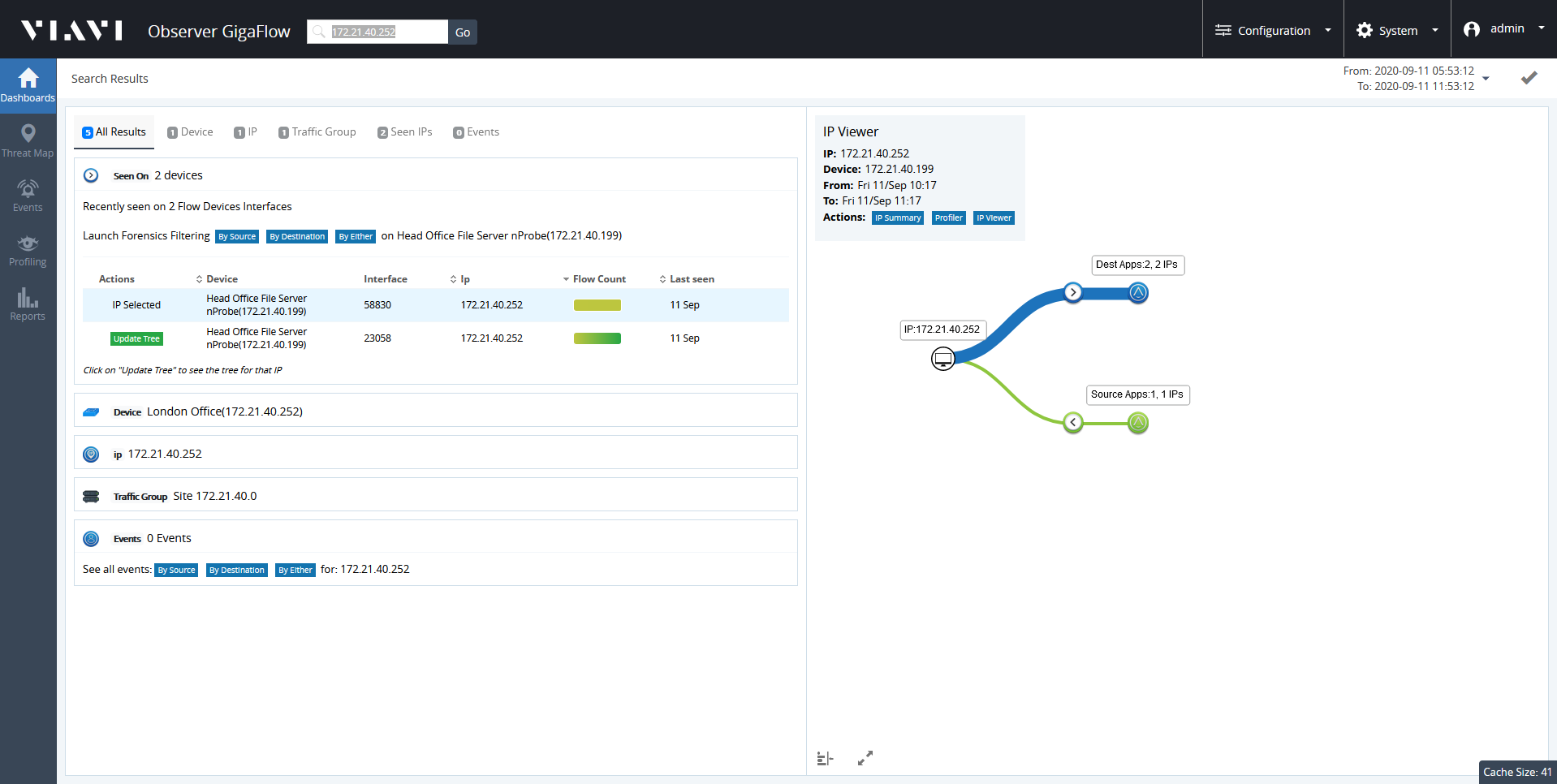
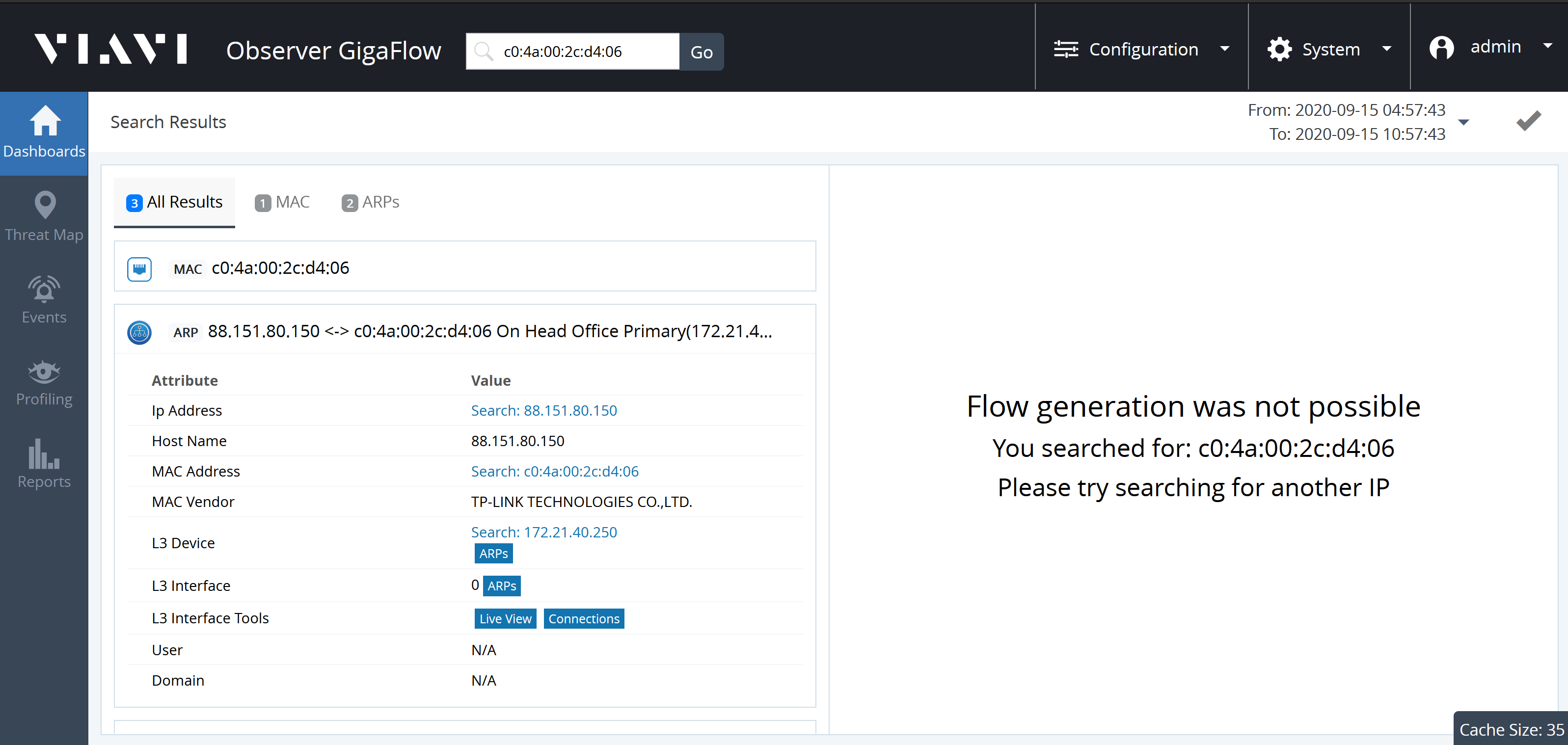
For example, searching for the MAC address c0:4a:00:2c:d4:06 on our demo network:
Expanding the MAC panel displays information:
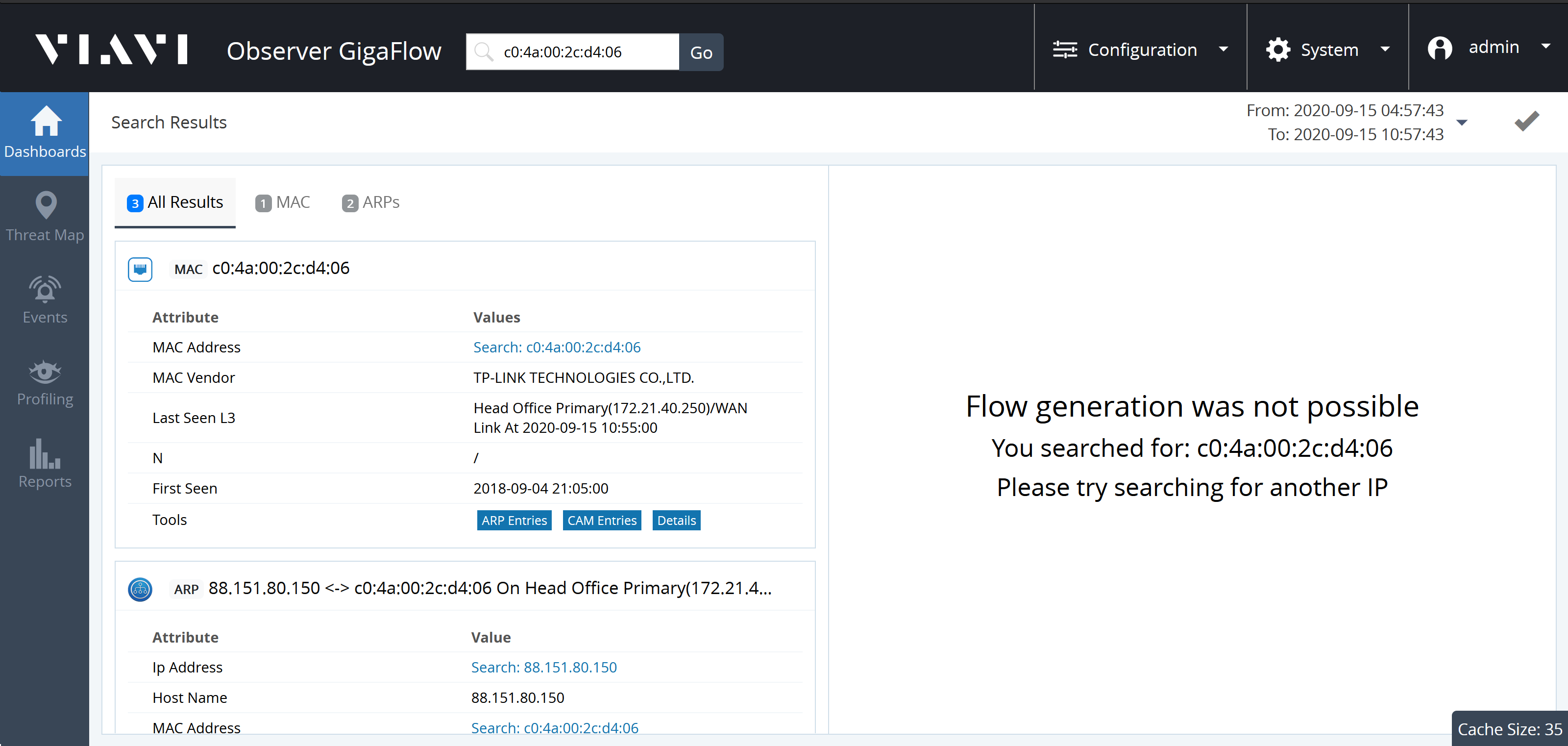
- MAC Address.
- MAC Vendor.
- Last Seen L3: Last seen on which Layer-3 device.
- N: .
- First Seen: date and time first seen on network.
- Tools: ARP Entries, CAM Entries, Details.
Selecting ARPs from the links in Tools brings up the relevant ARP entries. From here, you can click an interface to access more information about the physical interface the device is connected to. The interface with the lowest MAC count is the connected interface.
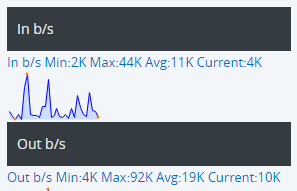
- Click Live Interface in the expanded ARPs panel to view the live in- and out- utilisation of the interface.
- Live View also provides speed, duplex and error count information for the interface.
- Click on Connections in the ARPs panel to see what other devices are connected to the same port.
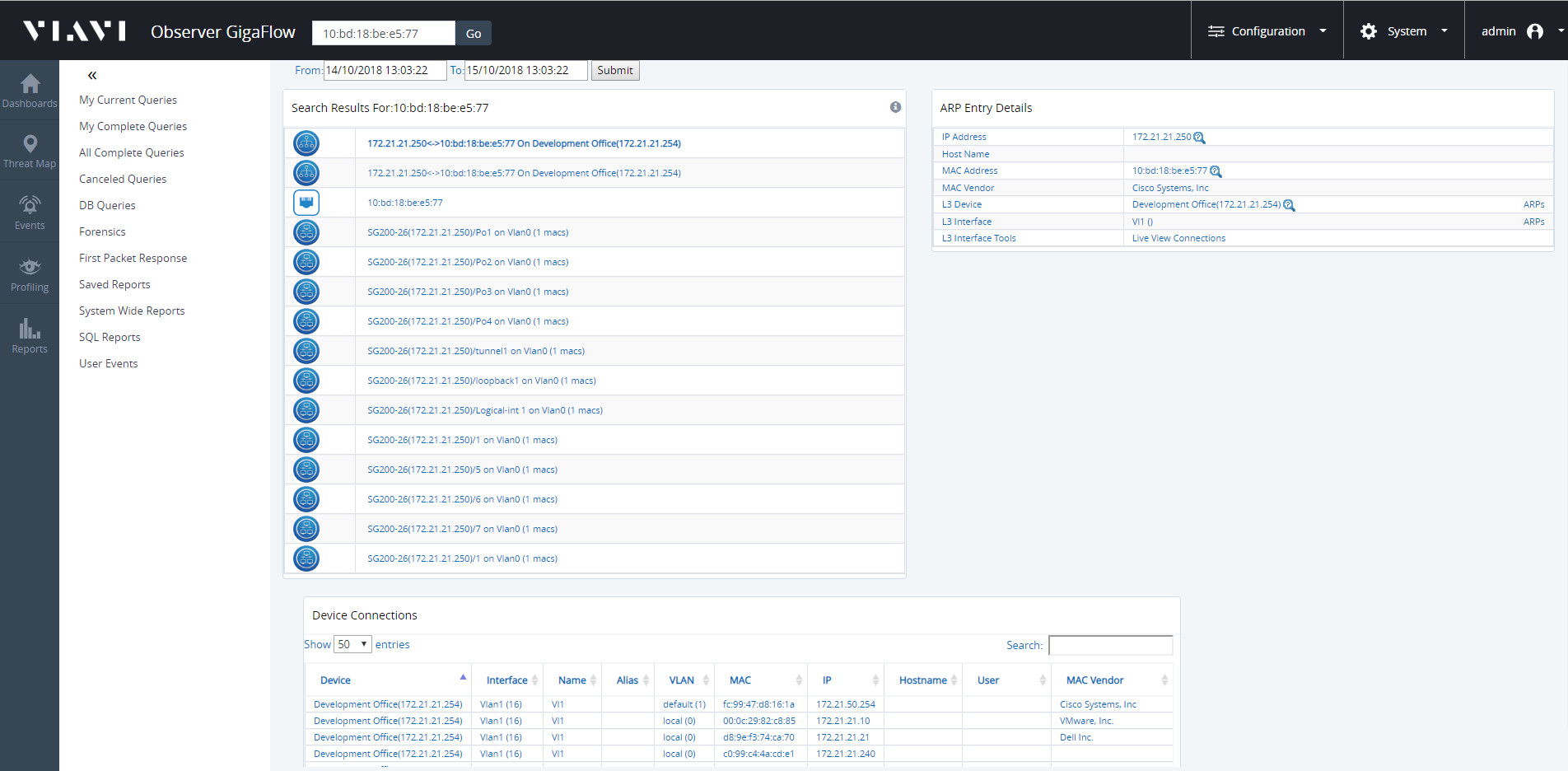
Blue boxed text indicates any piece of information that allows you to conduct a follow-on search:
- Click on the IP address follow-on search to find out if that address has been seen by any flow devices recently. The IP address search also shows any recent associated secflow data or events, i.e. blacklisted IP addresses and so on.
- Click on the MAC address follow-on search link to find out where the device is physically connected.
The Treeview, or Graphical Flow Map, will automatically load. This is a visual representation of the in- and out- traffic associated with a selected device.
To explore the Graphical Flow Map:
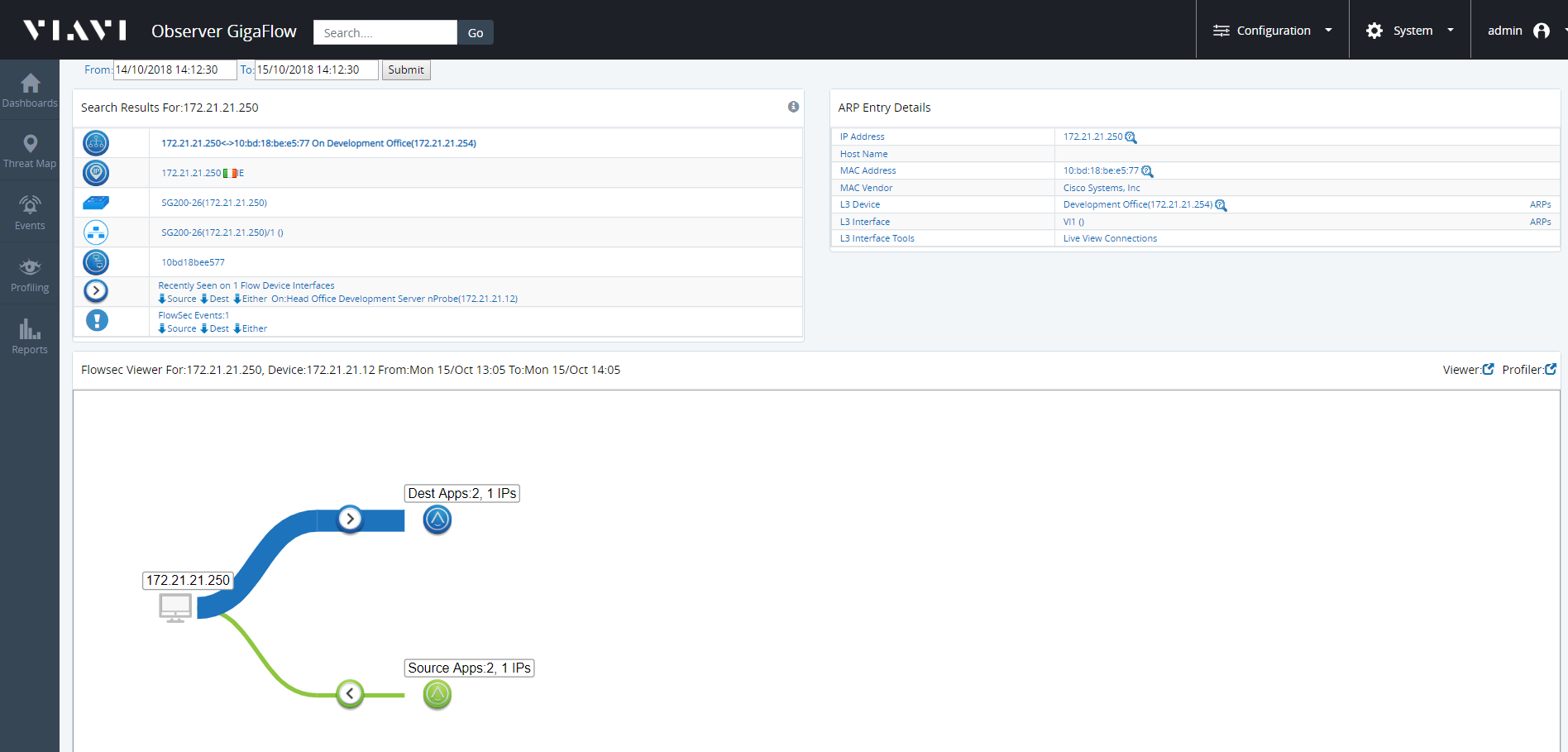
- Click on any icon to show more information.
- Click on the Destination Apps icon or the Source Apps icon for a breakdown of the applications. You can click on these to expand the tree.
- Move the pointer over icons to display the DNS Information of each device, showing how much traffic has been used.
- Click + to see more devices in a tree of many branches.
- The size of the line linking any two devices is proportional to the traffic volume between them.
- Click on any line in the Treeview table to filter only inbound or only outbound traffic. This will open a report showing traffic for the past two hours.
Search for a Username
- Enter a username, or part of a username, into the search box.
- GigaFlow will tell you if that username, or any variation of it, has been seen on your network.
- Click on any of the search results to display its associated information in the right-hand side panel.
- Click the associated IP address.
Search for a Network Switch
To search for a specific network switch:
- Enter the switch IP address into the search box.
- Click the icon beside the displayed switch; this will open the Device Connections table.
- The Device Connections table shows connections to any one port on any one VLAN.
- You can filter information by entering an interface, or device etc., into the search bar at the top-right of the table.
To make a follow-on search from a specific device or switch:
- Using switches from previously displayed tables, you can search for any switches of similar origin, e.g containing the same name elements.
- Click on the desired switch; this reopens the Device Connections table.
- You can also search by VLAN.
Apply a Macro (or Script) to a Switchport
Using GigaFlow Search, enter a known IP address associated with switch or the switch name and search:
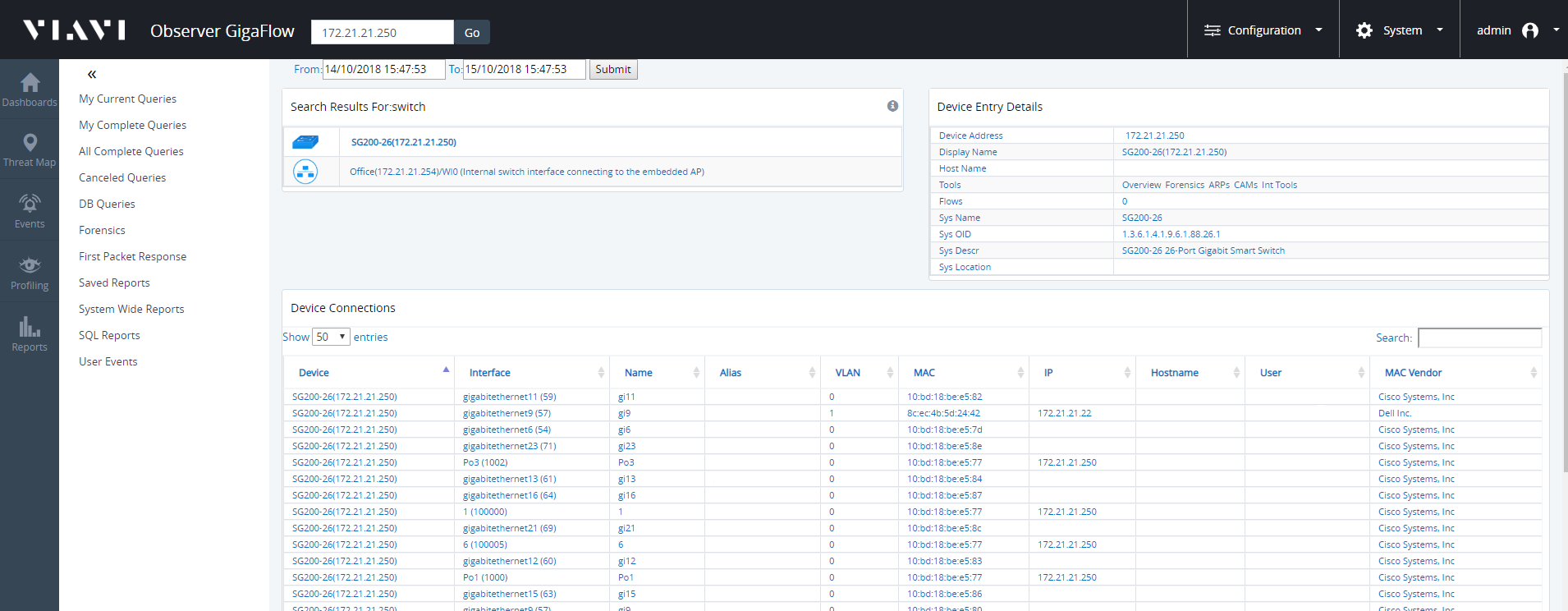
- Click on the the displayed switch name, in this case SG200-26(172.21.21.250).
- Click on Int Tools in the Tools section of the right-hand side panel.
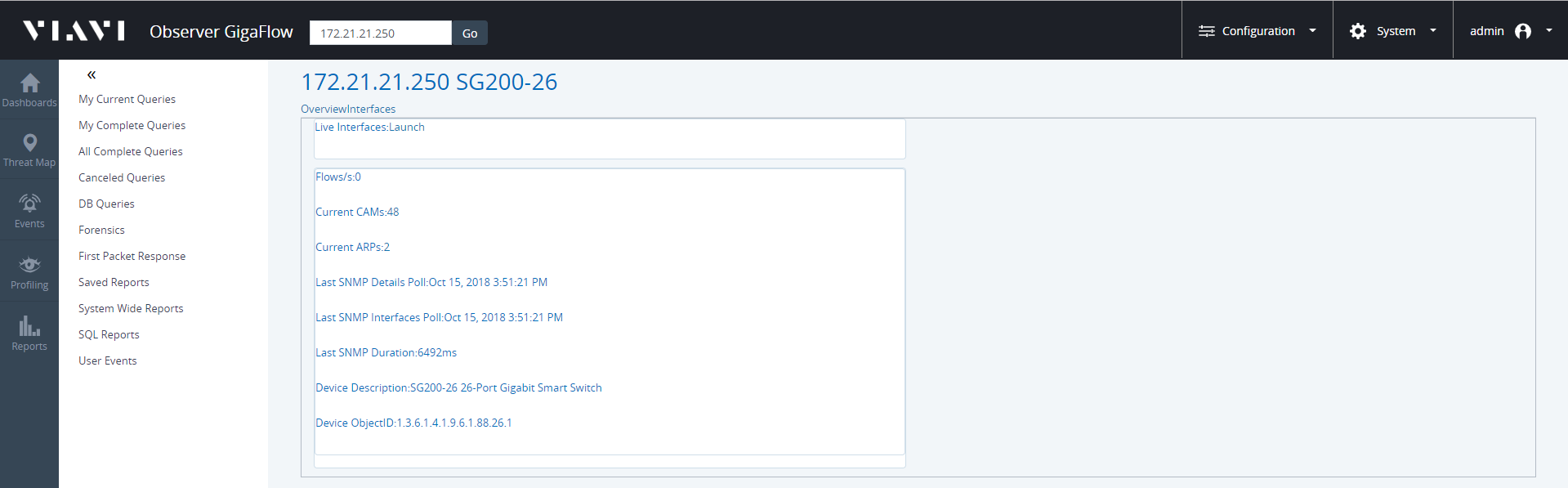
- Click on Interfaces next to Overview, at the top of the page.
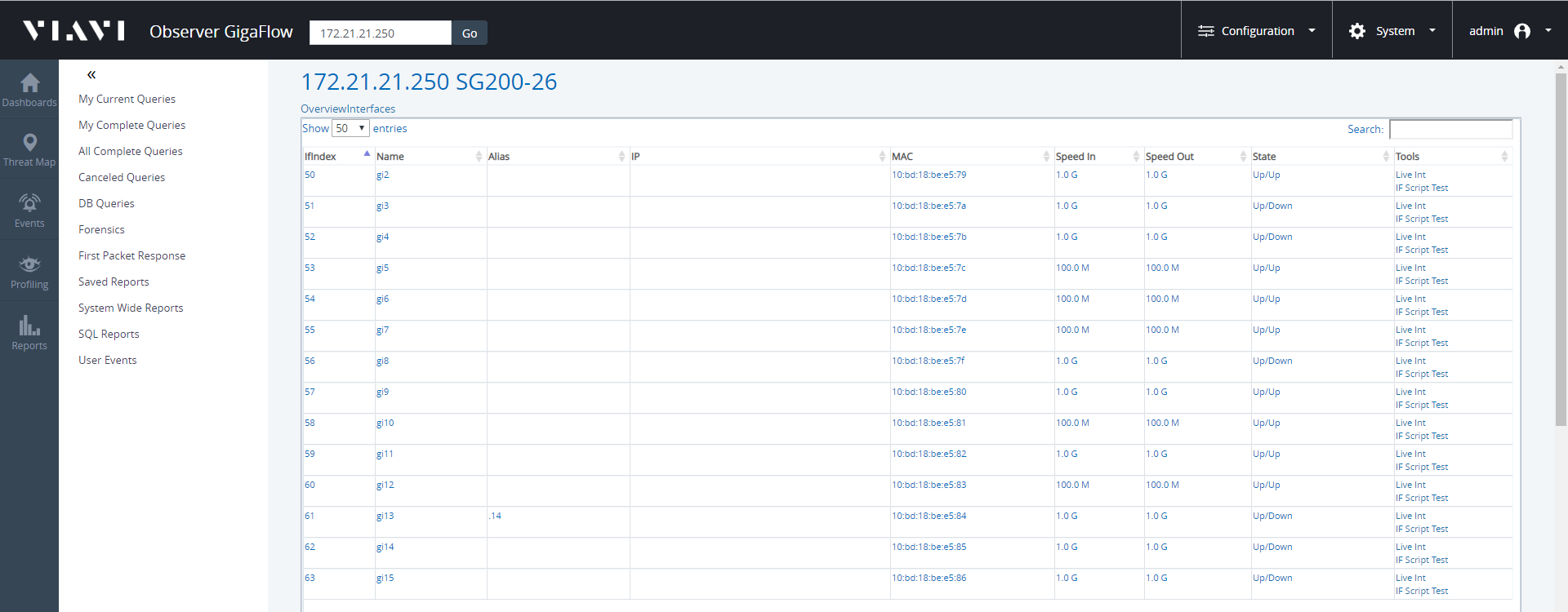
- Find the interface that the script will run on.
- On that interface click IF Script Test in the last column on the right.
- Add the ticket number into the description field.
- Select the script.
- Click Submit.
- GigaFlow will check that the interface is not an uplink to another switch.
- The script will be applied to the switch.
Diagnostics and Reporting
Explore Bandwidth Usage by Interface and Application
Select a site, device or remote branch directly from the Dashboard > Summary Device and Dashboard > Interface Summary pages. Use GigaFlow Search when the site, device or remote branch is not listed.
After searching by IP address, click on the Device Name in the panel on the left. The information in the panel on the right-hand side of the screen will refresh. Click Overview in the Tools section of this panel.
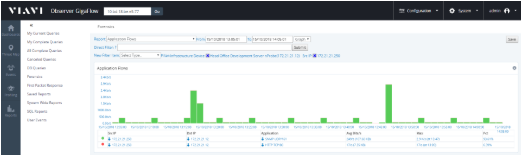
Figure: Sample results from GigaFlow's search for an internal IP address

In the Summary Interfaces panel, click on any interface to get overview information.
If you are interested in inbound - or download - traffic, select the Drill Down icon ![]() beside the interface name from the Summary Interfaces In panel.
beside the interface name from the Summary Interfaces In panel.
A list of the application traffic, ranked by volume, will be displayed here; this Application Flows report will include details of the internal IP address communicating with this application.
You can view historical flow data by selecting any date or time.
Identify Bandwidth Usage by User
Select a site, device or remote branch directly from the Dashboard > Summary Device and Dashboard > Interface Summary pages. Search using the main GigaFlow Search when the site, device or remote branch is not listed.
After searching by IP address, click on the Device Name in the panel on the left. The information in the panel on the right-hand side of the screen will refresh. Click Overview in the Tools section of this panel.
Figure: Sample results from GigaFlow's search for an internal IP address
In the Summary Interfaces panel, click on any interface to get an overview.
If you are interested in inbound - or download - traffic, select the Drill Down icon ![]() beside the interface name from the Summary Interfaces In panel.
beside the interface name from the Summary Interfaces In panel.
A list of the application traffic, ranked by volume, will be displayed here; this Application Flows report will include details of the internal IP address communicating with this application.
You can view historical flow data by selecting any date or time.
From the Report drop-down menu at the top of the screen, select Application Flows with Users and click submit  .
.
To see all traffic for a particular user, click the Drill Down icon ![]() to the left of that user. Click submit Forensics check and submit icon. once more.
to the left of that user. Click submit Forensics check and submit icon. once more.
Use First Packet Response to Understand Application Behaviour
First Packet Response (FPR) is a useful diagnostic tool, allowing you to compare the difference between the first packet time-stamp of a request flow and the first packet time-stamp of the corresponding response flow from a server. By comparing the FPR of a transaction with historical data, you can troubleshoot unusual application performance.
Application performance can be affected by many types of transaction: credit card transactions, DNS transactions, loyalty club reward transactions or any type of hosted transaction.
Ensure that First Packet Response (FPR) is enabled for each application. See Configuration > Server Subnets in the Reference Manual.
Select a site, a device or a remote branch directly from the Dashboard > Summary Device and Dashboard > Interface Summary pages. Access the Forensics report page by clicking the Drill Down icon ![]() in the Summary Devices table.
in the Summary Devices table.
Search using the main GigaFlow Search when the site, device or remote branch is not listed. After searching by IP address, click on the Device Name in the panel on the left. The information in the panel on the right-hand side of the screen will refresh. Click Forensics in the Tools section of this panel.
Figure: Sample results from GigaFlow's search for an internal IP address

The panel on the right is displayed when the IP address is selected in the left-hand side panel.
Whether you arrive via the Dashboard or using GigaFlow Search, the Forensics report page will open with an Application Flows report.
Select Applications from the drop-down Report menu. Click the Submit icon to refresh the Forensics report page.
For demonstration purposes, we are looking for credit card related application data not displayed in the most used applications graph. To any application not listed in the top applications, change the view from graph to table.
Select 100 entries.
After identifying the application associated with credit card transactions, click the Forensics Drill Down icon ![]() to the left of the application and choose Selected from the hover option list. Click Submit Forensics check and submit icon. again.
to the left of the application and choose Selected from the hover option list. Click Submit Forensics check and submit icon. again.
Select the All Fields Max FPR (First Packet Response) report type from the drop-down menu. Change the view from table to graph and click Submit .
GigaFlow will return the response times for credit card applications in the reporting period. By clicking on the graph or selecting from the calendar, you can view response times over the period. The application response times, along the y-axis, are given in milliseconds.
Determine if Bad Traffic is Affecting Your Network
Click Events in the main menu. GigaFlow will display information about the network events during the reporting period, including:
- A timeline of all events in the reporting period, the Events Graph.
Figure: Events Graph

- Infographic of the number of event types by date and time; this is the Event Types infographic. Circle size indicates the number of events.
- Infographic of the frequency of an event triggered by a particular source host by date and time; this is the Event Source Host(s) infographic. Circle size indicates frequency.
- Infographic of the frequency with which each infrastructure device was affected by an event by date and time, i.e. number of times per time interval; this is the Infrastructure Devices infographic. Circle size indicates frequency.
- Infographic of the frequency of occurence of particular event categories by date and time, i.e. number of times per time interval; this is the Event Categories infographic. Circle size indicates frequency.
Figure: Event Categories infographic

- Infographic of the frequency of an event targetted at a particular host by date and time, i.e. number of times per time interval; this is the Event Target Host(s) infographic. Circle size indicates frequency.
- Infographic of the frequency of an event by the measure of confidence in its identification, i.e. your confidence in the completeness and accuracy of the blacklist that the IP address was found in, and the severity of the threat to your network infrastructure, i.e. number of times per time interval; this is the Confidence & Severity infographic. Circle size indicates frequency.
Figure: Confidence & Severity infographic
 Confidence & Severity Infographic.
Confidence & Severity Infographic.
By clicking once on any legend item, you will be taken to a detailed report, e.g. detailed reports for each Event Type, Source Host, Infrastructure Device, Event Category and Target Host.
Identify any internal IP address from your network that appears on the Event Target Host(s) list. If an internal IP address appears on the list, the associated device is infected and communicating with a known threat on the internet. Click on the IP address to find out who it is communicating with.
Create a Script
See System > Event Scripts and the GigaFlow Wiki for more.
Create a Site
Sites are subnet and IP range aliases. Using sites can help you to identify problems within logical groupings of IP address, e.g. by site or subnet. Once a site is defined, GigaFlow will begin to record information about it.
To define a new site, click Configuration > Sites. Existing Sites are displayed in the main table. To add a new Site:
- Enter the name of the new site.
- Enter a description of the new site.
- Enter a start IP address for the site, e.g. 172.1.1.0.
- Enter an end IP address for the site, e.g. 172.1.1.255.
- Click Add Site to add the site.
To bulk-add new sites, i.e. more than one group at a time:
- Enter required site information using the format:
name,description,startip,endip - Use a new line for each new site.
To monitor defined sites, go to Profiling > Sites.
Sometimes, it can be useful to define a site by subnet and by infrastructure device. For example, a corporate network could have a subnet served by more than one router. To create a granular view of flow through each router, a separate site could be created for each router, defined by the IP range of the subnet as well as the device name. Type in the filter box to quickly identify a device.
To edit a site definition, click Configuration > Sites and click on the site name or on the adjacent Drill Down icon ![]() . This will bring up a new page for that site where you can edit the group definition.
. This will bring up a new page for that site where you can edit the group definition.
Create and Use a Profile
Profiling is a very powerful feature. A flow object is a logical set of defined flows and IP source and destination addresses. Flow objects make it possible to build up a complex profile or profiler quickly. These terms are used interchangeably. A particular network behaviour that involves network flow objects is described by a Profiler. Profiling allows you to congigure both the profiles of the flows to be tested, the entry flows, and the profiles of the allowed flows, i.e. the templates against which the entry flows are tested.
To get going, create your first profile. See Configuration > Profiling in the GigaFlow Reference Manual.
Step one is then to create a new flow object. To create a flow object:
- Go to Configuration > Profiling.
- Select the Apps/Objects tab.
- In the New Flow Object section, specify the flows that make up the object.
You can add ANDd existing profile(s) to the new flow object, i.e. the new definitions are added to the existing profile(s).
You can also select alternative existing profile(s) that this new profile also maps to (ORd), i.e. the new flow object uses either the new definitions or the existing flow object definitions.
To ANDd or ORd profile(s), use the drop-down menu in the flow object definitions and click the +.
As an example, a printer installation at a particular location connected to a particular router can be defined by a flow object that consists of:
- A printer flow object.
- ANDd a location flow object.
- ANDd a router flow object.
Or
- The flow object could define the IP address of a server and the web port(s).
A second flow object can be defined that will have its flow checked against the Allowed profile; this is an Entry profile.
To create a new Profiler (this term is used interchangeably with profile):
- Go to Configuration > Profiling.
- Give the new Profiler a name and description.
- Select an Entry profile (the profile to be monitored) and an Allowed profile (the acceptable profile) from the drop-down lists. The Entry and Allowed profile selection includes basic flow objects, i.e. individual devices on your network. A profile is a flow object that is itself a combination of flow objects.
- If you want to be alerted when an exception occurs, select Yes from the drop-down menu.
Select the Apps/Options tab.
GigaFlow comes loaded with a standard set of application port and protocol definitions. Flow records are associated with application names if there is a match.
Users can define their own application names within the software and have that application ID (Appid) available within the flow record. There are 3 techniques used, applied in order:
- Customers can define an application profile which lets them match traffic by source/destination IP address, source/destination port, source/destinaton MAC address, protocol, COS and/or nested rules.
- They can assign their own application names to specificed IP ports, i.e. create Named Applications.
- Or, if there are no user defined settings, the software will select the lowest port.
Select the Apps/Options tab.
To create a new Defined Application:
- Go to Configuration > Profiling.
- Select the Apps/Objects tab.
- In the New Defined Application section, specify a name, a description and select the flow object that is associated with the application.
- Click + to add the application.
The Realtime Profiling Status at Profiling > Realtime Overview shows realtime data on defined Profilers. The display updates every 5 seconds and shows:
- Profiler: this is the defined profile.
- Clients: the number of connected devices.
- Hits: the number of flow records that have matched the allowed flows.
- Exceptions: the flow records for this profile that have deviated from the ideal, or Allowed, profile. See Configuration > Profiling.
The Profiling Event Dashboard at Profiling > Profiling Events gives an overview of profile events.
At the top of the page you can set both the reporting period and resolution, from one minute to 4 weeks.
The Profiles infographic shows a timeline of the number of events with the profile(s) involved. Circle diameters represent the number of events. The peak number of events in the timeline for each profile are highlighted in red.
The Severities infographic shows a timeline of the number of events along with their estimated severity level(s). Circle diameters represent the number of events. The peak number of events in the timeline for each severity level are highlighted in red.
The Event Entries table gives a breakdown of profile events with the following entries:
- The unique event ID number.
- The time at which event occurred.
- The category or profile name.
- The severity of the event as a percentage.
- The source IP address.
- The target IP address.
- The application, user defined if it exists. See also Configuration > Profiling and Flow Details.
- Any information other error/status message, e.g. Profiler Exception.
A drop-down selector lets you choose the number of the most events to display.
To access a detailed overview of any flow, click on the adjacent Drill Down icon
![]() . This provides a complete overview of that flow, listing:
. This provides a complete overview of that flow, listing:
- The source address, a link to search forensics and any associated blacklists.
- Source MAC address.
- Destination address, a link to search forensics and any associated blacklists.
- Destination MAC address.
- Source port.
- Destination port.
- Appid: the application ID is a unique identifier for each application.
In GigaFlow, Appid is a positive or negative integer value. The way in which the Appid is generated depends on which of the 3 ways the application is defined within the system. Following the hierarchy outlined in Configuration > Profiling -- Apps/Options -- Defined Applications, a negative unique integer value is assigned if (1) the application is associated with a Profile Object or (2) if it is named in the system. If the application is given by its port number only (3), a unique positive integer value is generated that is a function of the lowest port number and the IP protocol.
- Application. See Appid, above, and Configuration > Profiling.
- Number of packets in flow.
- Number of bytes.
- User.
- Domain.
- Fwevent. See
- Fwextcode.
- Profile, e.g. PCs.
- Net device IP address, name and number of flows.
- In-Interface.
- Out-Interface.
See Glossary for more about flow record fields used by GigaFlow.
See also Search for instructions to access the Graphical Flow Mapping feature.
By clicking any Category, Severity, Source IP or Target IP in the Event Entries table, you will be taken to a version of the Events Dashboard filtered for that item.
See Dashboards > Events for an overview of the structure of this page.
Create an Integration
An integration allows you to call defined external web pages or scripts directly from the Device Interface Overview page. To add an integration, navigate to System > Global. In the Integrations settings box, you can add or change an integration.
There are two types of integration:
- Device: where you can pass the device IP address.
- Interface: where you can pass the device IP address and the ifIndex of the interface being used.
To add an integration:
- Enter a new name, e.g. "Interface Action 1".
- Select the type of target, i.e. a device or an interface. These map to the IP address of the device and the ifIndex of the interface.
- Select the type of action, i.e. will the integration work with a web page or a script.
- Enter the web page URL or select a script.
- Enter inputs to be passed via the website or script.
- Click Save to save changes.
Example 1
In the code below, the populated field tells the software that you want to populate the device field with the IP address and the ifindex field with the ifindex. These fields (device and ifindex) will be passed to the target. We also have required fields, which are fields which the user is required to populate.
{
'populated':{
'device':'flow_device',
'ifindex':'flow_ifindex'
},
'required':[
{'name':'user','display':,'type':'text','value':},
{'name':'password','display':'Password','type':'password'},
{'name':'macro','display':'What Macro?','type':'select','data':['macro1','macro2','macro3','macro4']}
]
}
Example 2:
- Web URL http://www.example.com/?device=flow_device&interface=flow_ifindex
- This scripts prints the collected information. It then runs dir and outputs the results.
var ProcessBuilder = Java.type('java.lang.ProcessBuilder');
var BufferedReader = Java.type('java.io.BufferedReader');
var InputStreamReader= Java.type('java.io.InputStreamReader');
output.append(data);
output.append("Device IP:"+data.get("device")+"
");
output.append("IFIndex:"+data.get("ifindex")+"
");
try {
// Use a ProcessBuilder
//var pb = new ProcessBuilder("ls","-lrt","/"); //linux
var pb = new ProcessBuilder("cmd.exe", "/C", "dir"); //windows
output.append("Command Run");
var p = pb.start();
var is = p.getInputStream();
var br = new BufferedReader(new InputStreamReader(is));
var line = null;
while ((line = br.readLine()) != null) {
output.append(line+"");
}
var r = p.waitFor(); // Let the process finish.
if (r == 0) { // No error
// run cmd2.
}
output.append("All Done");
} catch ( e) {
output.append(e.printStackTrace());
}
log.warn("end")
See System > Global in the Reference Manual for more.
Respond to a Blacklist Email Alert
Alerts and Events
See System > Alerting in the Reference Manual to enable email alerts.
You will receive a GigaFlow alert email when a device in your network makes a connection to a blacklisted IP address. The embedded link will direct you to an Events page that summarises interactions with the blacklisted IP address during the reporting period.
See Determine if Bad Traffic is Affecting Your Network for more.
Determine the Importance of an Event
If you receive intelligence about a specific IP Address, MAC Address, network device or user, carry out a GigaFlow Search on the object. For this example, we will search by IP address.
After searching by IP address, click By Either in the panel on the left.
This will bring you to an Events page that summarises interactions with the IP address during the reporting period. Using this information, you can build a picture of the importance of the event.
See Determine if Bad Traffic is Affecting Your Network for more.
To view historical information, select the relevant dates and times at the top of the page.
Investigate a SYN Anomaly
See Reports > System Wide Reports > SYN Forensics Monitoring in the Reference Manual.
GigaFlow monitors all TCP flows where only the SYN bit is set. In normal network operations, this indicates that a flow has not seen a reply packet while active in a router's Netflow cache.
A lonely SYN can be an indicator that:
- Routing was asymmetric. Perhaps the reply returned via a different router.
- Reply traffic was blocked.
- Servers were not responding for some reason.
- Something was probing the network.
To view objects that are behaving anomalously, navigate to Reports > System Wide Reports > SYN Forensics Monitoring
You will see a summary of all the internal sources listed in order of the number of destination objects associated with each internal source.
Click the Drill Down icon for more information about each IP address.
Extract a GigaStor trace file
The Trace extraction functionality allows you to pull a packet capture out of a specified GigaStor as a .pcap file, which you can download on your machine.
To create a trace extraction, you need to access the Forensics page corresponding to the device that you want. You will find there the Trace Extraction icon that provides access to the trace extraction parameters.
Apply filters to the selected device before creating the packet capture. This narrows the scope (and disk space required) of the packet capture. For more information, see the filtering syntax documentation.
Each trace extraction request is considered a job, and a packet capture is the result of each successful job. Every trace extraction job has its own progress including a start and end. You can make multiple, concurrent trace extraction jobs that are queued in the order they were received. The next trace extraction job in queue begins after the first job completes, either successfully or by failure. To maintain optimal disk performance on the GigaStor system, only one job is active at any given time on each GigaStor.
The list of created packet capture files is available from Reports > Trace Extraction Jobs.
You can configure how Trace Extraction is used in GigaFlow from System > Global > GigaStor.
To create a Trace Extraction:
- Access the Forensics page for the IP address that you want to investigate.
- Filter the forensic data using the available filters. Note that only the following filters are taken into acount in the packet capture:
- IP Address Pair
- MAC Address
- MAC Address Pair
- Port Number(s)
- Click the Trace Extraction icon from the top side of the page.

- The GIGASTOR TRACE EXTRACTION PARAMETERS dialog opens. You can edit here the following details:
- GigaStor: the Gigastor from where the packets are extracted.
- Filename: the packet capture file (.pacp) name.
- Filter: you can add more filters, taking into account the filtering syntax.

- Click Save. A trace extraction job request is created. The Trace Extraction Jobs opens, providing the following job details:
- Job name.
- Creation date.
- Completion status.
- File size. Note that, when applying fewer filters or none, the size of the generated packet capture file can be very large.
- Start and end time.
- Applied filter.

To view your trace extraction jobs, check their status and download the generated packet capture files, go to Reports > Trace Extraction Jobs.
Configuration and System Set-up
Working with Clusters of GigaFlow Servers from Viavi Apex
See also System > GigaFlow Cluster.
Overview
A single GigaFlow server can be configured to search for IP addresses across many remote GigaFlow servers directly from Viavi's Apex system. This feature is useful for large organisations that may have many GigaFlow servers monitoring different networks within the organisation, e.g. in different regions. The central administrator may want a view across the entire network, e.g. to determine if a particular suspect IP address has been recorded by routers on different networks.
In this example, assume that you, as the main administrator, want visibility on several remote GigaFlow servers.
The set-up is:
- GigaFlow Server #0: this is the server at HQ, used by the main administrator. We call this the Pitcher.
- GigaFlow Server #1: this is remote GigaFlow server #1. We call this Receiver 1.
- GigaFlow Server #2: this is remote GigaFlow server #2. We call this Receiver 2.
- GigaFlow Server #3: this is remote GigaFlow server #3. We call this Receiver 3.
Figure: Defining a GigaFlow cluster
Configure the Cluster
Log in to GigaFlow Server #0, the Pitcher, and navigate to System > GigaFlow Cluster.
In the This Server panel, you will see a pre-generated unique secret. Leave this as is.
In another browser tab or window, log into Receiver 1 (GigaFlow Server #1). Copy the unique secret from Receiver 1's This Server panel. You do not need to do anything with the New Cluster Server panel on the receivers.
Figure: This Server panel

Switch back to the Pitcher (GigaFlow Server #0). In the New Cluster Server panel, perform the following steps:
- In the Remote Server Name field, enter the name of a server that Apex returns when you search across the GigaFlow servers (for example, Receiver 1).
- In the Remote Server Description field, enter the description that shows when you hover over the server name when you search across the GigaFlow servers, (for example, EMEA GigaFlow server Receiver 1).
- In the Remote Server URL field, enter the full IP address, including the port number, used to connect to Receiver 1, (for example, in the format
http(s)://172.1.1.0:22 ). - In the My IP Address field, enter the IP address of the Pitcher system as seen by Receiver 1.
Note:
This IP address is used by the Pitcher to generate a secure hashed key for communication. The receiver reverses this hash using, among other things, the IP address of the Pitcher. An intermediate firewall (NAT) could create problems if the Pitcher does not create the hashed key using the IP address seen by the receiver. - In the Admin User ID field, enter the UserID used when making superuser calls to Receiver 1 (for example, Admin). This is used during this set-up process.
- In the Standard User field, enter the UserID used when making report requests, (for example, reportuser). This is used by all the clients when collecting data from the receiver.
Note:
This user must exist on Receiver 1. If it does not exist, then switch to Receiver 1 and create a new normal user on Receiver 1 (for example, reportuser). - In the Server Shared Secret field, paste Receiver 1's secret (for example, the key copied from Receiver 1's This Server panel).
- Click the Add New Cluster Server button to add Receiver 1.
- Repeat this process for Receiver 2 and Receiver 3.
RESULT: The Pitcher connects to Receiver 1 using the Admin user to verify that everything is correct and to populate the table in the Cluster Access frame, on the System - GigaFlow Cluster page. Receiver 1 shows in the main table.
Figure: New Cluster Server panel

The cluster server feature is flexible, this means that a receiver in one cluster can be a pitcher for another. |
If you use the clustering feature of GigaFow, then make sure that the Access-Control-Allow-Origin field from the System > Global > General page is set to * (asterisk) instead of the none default value, to allow the browser to access the page. |
Search the GigaFlow Cluster
Figure: Conducting a GigaFlow Cluster search
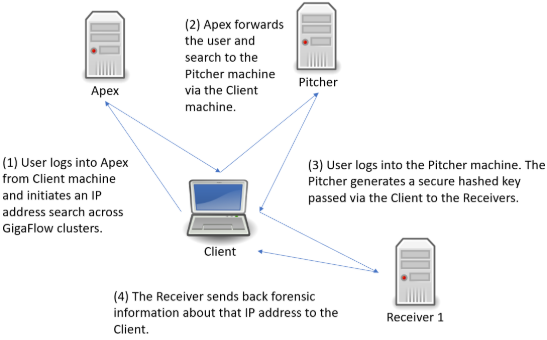
Following the search link from Apex, you will be brought to a new tab and the log in screen for the Pitcher machine. After logging in, you will be brought to the GigaFlow Cluster report page.
Figure: The initial view of the GigaFlow Cluster report page

This displays a list of hits for this IP address across the cluster; in this example, the IP address 172.21.21.21 was found on 11 devices monitored by three receivers. On these receivers the system found 9 devices with data matching the search and there were no errors.
In the first first table, each GigaFlow server is listed with:
- Server name.
- The URL to connect to the server; follow this link to access the full UI for that particular server.
- The type of result; in this case flows.
- Which device monitored by this server had the data.
- Device details: name, interface and the number of flows seen.
- A number and visualization of the data size; this is a ranking of result relevance.
- A drill-down link to forensics data for each result. A full view into the receiver is displayed below the top table; this allows you to view the results and interact with that GigaFlow server without having to leave this page.
Figure: Clicking on the drill down icon beside a result brings up the full user interface and a forensics report for that device on the associated GigaFlow server

The system allows ten minutes between running the report and viewing these results without re-authentication.
You can also select different report types to run on that device on that GigaFlow server by selecting from the drop-down menu. See Reports > Forensics in the main Reference Manual for more.
Encryption and GigaFlow Clusters
Communication between all clients in a Gigaflow cluster is IP to IP, i.e. unicast. The traffic is routed over https, using TLS based on certificates.
FAQs and Troubleshooting
Which Web Browers Are Supported by GigaFlow?
We test against the latest Mozilla Firefox, MicroSoft Edge and Google Chrome browsers.
What Server Specification Do We Need?
See GigaFlow Server Sizing page for a useful server size calculator.
Flows and Server Sizing
GigaFlow has been tested and certified to support up to 1,000 concurrent devices or up to 40,000 flows per second (flow/s) from less than 20 devices.
The flow rate changes with the number of connected devices as follows:
| Flow/s | Number of Devices |
|---|---|
| 50,000 | 10 |
| 40,000 | 20 |
| 20,000 | 40 |
| 10,000 | 80 |
| 5,000 | 160 |
| 2,500 | 300 |
| 1,250 | 600 |
| 1,000 | 1,000 |
Disk Throughput for Flow Writing to Database
Allow for at least 600 bytes per flow record per second for I/O throughput, i.e.
| Flow/s | Bytes/s (Sustained Write Performance) | MB/s (Sustained Write Performance) |
|---|---|---|
| 100 | 60,000 | 0.06 |
| 2,000 | 1,200,000 | 1.2 |
| 10,000 | 6,000,000 | 6.0 |
| 40,000 | 24,000,000 | 24.0 |
Disk I/O for Flow Writing To Database
With
f = flow/s
d = number of devices
I = Input/Output performance measurement (IOP), nominally sustained sequential writing.
I = 20 + (f / 500) + (d / 5)
i.e. allow for a base of 20 IOPs, add an additional 1 IOP/s for every 500 flow/s and another 1 IOP/s for every 5 devices.
| Flow/s | Number of Devices | IOPs |
|---|---|---|
| 1,000 | 1,000 | 222 |
| 5,000 | 1,000 | 230 |
| 10,000 | 100 | 60 |
| 40,000 | 10 | 102 |
Disk I/O for Flow Reading from Database
Allow for at least 100 IOPs read.
Disk Sizing
The server must support at least 300 MB/s sustained read and write to handle the peak device or flow count. Anything less than this will result in dropped flows. For Linux, we recommend EXT4 or XFS file systems as well a dedicated RAID partition for the database. Adding a hardware RAID controller that supports RAID 10, or at least RAID 5, will improve performance and provide hardware redundancy. The amount of storage required is directly related to the flow rate and features enabled.
| Data Type | Minimum Space Per Record (Bytes) |
|---|---|
| Forensics Flow | 250 |
| Event Record | 900 |
500 flow/s of forensics == 450 MB per hour == 11 GB disk space per day.
RAM Sizing
A basic installation should have 4 GB RAM available for the OS and additional 50 MB per device to monitor. More RAM will always improve performance:
| Number of Devices | Minimum RAM (GB) |
|---|---|
| 10 | 4.5 |
| 100 | 9 |
| 500 | 29 |
| 1,000 | 54 |
CPU Sizing
CPU sizing in GigaFlow is based on the Postgre SQL database. Overall performance is also dependent on CPU performance.
While there is little to gain by going beyond 8 cores, more powerful CPUs will provide a better experience. Intel's Xeon X5680 3GHz or Core i7-3770S 3GHz are recommended as a minimum required specification.
Experimental Results
As a demonstration, GigaFlow was installed on a typical server with the following specifications:
- HP DL360 Gen 6.
- 72 GB RAM.
- 2x 8 core (Intel Xeon, E5530 @ 2.40GHZ).
- 4x 146 GB SAS 10K RPM drives (432320-001 3GB/s) in a RAID 10 configuration.
- P410i RAID controller with 1 GB RAM.
- Linux CentOS 7, single partition.
The results of a performance test were as follows:
| Devices | Flows | Total Flows | CPU Idle | Disk Write | IO Writes | Disk Utilisation | Notes |
| - | per device s-1 | - | % | MB s-1 | s-1 | % | - |
| 10 | 15,000 | 15,0000 | 80 | 88 | 250 | 9 | |
| 50 | 3,000 | 150,000 | 78 | 91 | 260 | 11 | |
| 100 | 1,500 | 150,000 | 78 | 91 | 261 | 11 | At limit of flow cache before flows are dropped. |
| 250 | 400 | 100,000 | 85 | 62 | 142 | 5 | Must double RAM used by GigaFlow to 1,536 MB. |
| 500 | 200 | 100,000 | 86 | 58 | 190 | 10 | Must double RAM used by GigaFlow to 1,536 MB. |
| 1,000 | 100 | 100,000 | 85 | 59 | 232 | 10 | Must double RAM used by GigaFlow to 1,536 MB. |
| 2,000 | 50 | 100,000 | 82 | 59 | 220 | 10 | Must double RAM used by GigaFlow to 1,536 MB. |
These results show that this relatively mid-specification machine can cope with 50 devices at 150K flows per second. The same system can handle 2,000 devices with a cumulative count of 100K flows/s.
We recommend a maximum of 1,000 devices per GigaFlow server. Above this, database query performance will degrade.
Does GigaFlow have an API?
Yes, there is a REST endpoint for all report data with a portal user definitions to control access. You can open your GigaFlow system for integration with third party applications.
For more information, see API articles at the official GigaFlow Wiki.
Does GigaFlow Require a Client?
No, your GigaFlow system is accessed via a HTML/Javascript front-end using your preferred browser. Output is rendered as HTML, .csv or .pdf.
Reference Manual for GigaFlow
Log in
Figure: GigaFlow's login screen

Log in to GigaFlow from any browser using your credentials. GigaFlow will open on the Dashboards welcome screen.
User Interface Overview
Layout
Left Menu Items
The left menu contains links to the main outputs from GigaFlow.
Figure: Detail of the left main menu

Top Menu Items
The top menu contains links to system configuration, system settings and user settings.
Figure: Detail of the top main menu

Features
Documentation and Help
Most items in GigaFlow will have a white information button on a gray background at the top right. Click this to link out to the relevant section in the GigaFlow Reference Manual.
Refresh Button
You can refresh any page in GigaFlow using the browser refresh button.
Timeline Graphs
By clicking, holding and dragging left or right, you can create a report for any shorter time period.
Figure: Click and drag to create a report for a particular timeframe within a timeline

The user selects a shorter time period of interest by clicking and dragging, in this case from just before 11:00 to just before 11:15.
Figure: Re-scaled timeline

The timeline is re-drawn for the selected time period. All associated information on this page is recalculated, i.e. tables and graphs.
Colors
Throughout GigaFlow, all hyperlinks are colored blue.
GigaFlow Search
Overview
Search Scope
The system search is at the top of every GigaFlow page; it is a powerful and convenient way to access information directly, returning relevant matches and detailed summary information.
The left hand side of the search results screen displays summary information about that IP address, including:
- Infrastructure device(s) that this IP address was seen on.
- More information about the associated device.
- Associated interfaces.
- Detail about the IP address.
- Associated traffic groups.
- Associated ARP entries.
- Associated LLDP entries.
- Associated events, e.g. watchlist or profile alerts.
The Treeview, a kind of graphical flow mapping, will automatically load on the right hand side of the search results screen. This is a visual representation of the in- and out- traffic associated with a selected device.
See Search > Graphical Flow Mapping for more.
Searching by IP Address
- Enter an IP address in the Search box.
- Click Go.
- Select a reporting period and click Submit .
Figure: GigaFlow's search bar and results screen. In this screenshot, the user is searching for an IP address, 172.21.21.254.

Scrolling down reveals additional results:

Click to expand. The tabbed box on the left displays search results for that IP address, including any infrastructure device that it is associated with, the number of interfaces it was recently seen on, IP entry details, ARP entries and the number of secflow events associated with it.
Each item can be clicked to display more information and follow-on searches can be carried out for linked information, e.g. for associated MAC addresses.
Searching by MAC Address
GigaFlow can search by MAC address. This returns the name of the connected device and its VLAN.
To search by MAC address:
- Enter the entire MAC address into the search box.
- GigaFlow's MAC address search works for any standard MAC address format.
After searching the MAC address a number of key pieces of information will be displayed, including:
- IP address.
- Host name.
- MAC vendor.
- Layer-3 devices, interfaces or interface tools.
From here, some of the other actions you can take include:
- Click the interface displayed in the left had dialog box to access more information about the physical interface the device is connected to. The interface with the lowest MAC count is the connected interface.
- Click Live View on the right to display the live in- and out- utilisation of the interface.
- Live View also provides speed, duplex and error count information for the interface.
- Click on Connections to see what other devices are connected to the same port.
Searching by Username
To search by username:
- Enter a username, or part of a username, into the search box.
- GigaFlow will tell you if that username, or any variation of it, has been seen on your network.
- Click on any of the search results to display its associated information in the right-hand side panel.
Searching for a Specific Network Switch
To search for a specific network switch:
- Enter the switch IP address into the search box.
- Click to expand the Device information and click, See all connections.
- The Device Connections table shows connections to any one port on any one VLAN.
- You can filter information by entering an interface, or device etc., into the search bar at the top-right of the table.
To make a follow-on search from a specific device or switch:
- Using switches from previously displayed tables, you can search for any switches of similar origin, e.g containing the prefix of PATS-3560.
- Click on the desired switch; this reopens the Device Connections table.
- You can also search by VLAN.
Graphical Flow Mapping
GigaFlow Search provides access to the Graphical Flow Mapping feature. Searching for any IP address returns summary tables as well as a visualisation of flows during the reporting period selected.
To access this feature, search for an IP address. See Searching by IP Address above.
On the right hand side of the screen, you will see the Graphical Flow Map.
Figure: GigaFlow's Graphical Flow Map

The Graphical Flow Map is an interactive visualisation of the flows associated with that IP address. The branches of the Graphical Flow Map can be expanded to show associated interfaces and destination and source devices. These in turn can be explored.
To explore the Graphical Flow Map:
- Click on any icon to show more information.
- Click on the Destination Apps icon or the Source Apps icon for a breakdown of the applications. You can click on these to expand the tree.
- Click + to see more devices in a tree of many branches.
- The size of the line linking any two devices is proportional to the traffic volume between them.
- Click on any line in the Treeview table to filter only inbound or only outbound traffic. This will open a report showing traffic for the past two hours.
See also Profiling > Events > Flow Details
Dashboards
After logging in, you will see the Server Overview Dashboard. From here you have direct access to some of GigaFlow's main functions.
Figure: GigaFlow's main dashboard

Enterprise Dashboard
Located at Dashboards > Enterprise Dashboard.
Top Devices (Last Hour v Last Week Hour)
This is a summary of traffic across the busiest infrastructure devices over the past hour. Infrastructure devices are routers sending flow as well as other Layer-2 devices that are not sending flow but sending ARP and CAM Tables. The information displayed includes:
- Avg Bits/s: average traffic per second per device.
- Percentage: this is the proportion of all traffic over the past hour seen by a particular system/router.
- Position relative to the same hour last week: this is the percentage increase or decrease in traffic per second per device compared with the same hour last week.
When more than ten devices are registered, the full list can be displayed by clicking the drill down icon. This displays a tabular version of all the data, with a CSV export option.
Top Interfaces (Last Hour v Last Week Hour)
This is a summary of traffic across the busiest interfaces over the past hour. The information displayed includes:
- Avg Bits/s: average traffic per second.
- Max: this is maximum traffic volume seen in the data set.
- Percentage: this is the proportion of all traffic seen by a particular interface.
- Position relative to the same hour last week: this is the percentage increase or decrease in traffic per second per interface compared with the same hour last week.
When more than ten interfaces are registered, the full list can be displayed by clicking the drill down icon. This displays a tabular version of all the data, with a CSV export option.
See Configuration > Infrastructure Devices for setup instructions.
Top Sites (Last Hour v Last Week Hour)
This graph shows the traffic associated with the busiest sites over the past hour. The information displayed includes:
- Avg Bits/s: average traffic per second per site.
- Percentage: this is the proportion of all traffic over the past hour seen by a particular site.
- Position relative to the same hour last week: this is the percentage increase or decrease in traffic per second per site compared with the same hour last week.
When more than ten sites are registered, the full list can be displayed by clicking the drill down icon. This displays a tabular version of all the data, with a CSV export option.
Top Applications (Last Hour v Last Week Hour)
This graph shows the traffic associated with the busiest applications over the past hour. The information displayed includes:
- Avg Bits/s: average traffic per second per application.
- Percentage: this is the proportion of all traffic over the past hour seen by a particular application.
- Position relative to the same hour last week: this is the percentage increase or decrease in traffic per second per application compared with the same hour last week.
When more than ten applications are registered, the full list can be displayed by clicking the drill down icon. This displays a tabular version of all the data, with a CSV export option.
Top Source Addresses (Last Hour v Last Week Hour)
This graph shows the traffic associated with the busiest source IPs in the past hour. The information displayed includes:
- Avg Bits/s: average traffic per second per source IP.
- Percentage: this is the proportion of all traffic over the past hour seen by a particular source IP.
- Position relative to the same hour last week: this is the percentage increase or decrease in traffic per second per source IP compared with the same hour last week.
When more than 10 IP addresses are registered, the full list can be displayed by clicking the drill down icon. This displays a tabular version of all the data, with a CSV export option.
Top Destination Addresses (Last Hour v Last Week Hour)
This graph shows the traffic associated with the busiest destination IPs in the past hour. The information displayed includes:
- Avg Bits/s: average traffic per second per source IP.
- Percentage: this is the proportion of all traffic over the past hour seen by a particular destination IP.
- Position relative to the same hour last week: this is the percentage increase or decrease in traffic per second per destination IP compared with the same hour last week.
When more than 10 IP addresses are registered, the full list can be displayed by clicking the drill down icon. This displays a tabular version of all the data, with a CSV export option.
Server Overview
Located at Dashboards > Server Overview.
Figure: Detail of the left main menu and Dashboards submenu.
This default welcome screen shows summary server flow information with three main sections:
Summary Devices
This is a summary of traffic across all of your infrastructure devices ranked by the busiest network device. Infrastructure devices are routers sending flow as well as other Layer-2 devices that are not sending flow but sending ARP and CAM Tables. The information displayed includes:
- Avg Bits/s: average traffic per second.
- Max: this is maximum traffic volume seen in the data set.
- Percentage: this is the proportion of all traffic seen by particular system/router.
The bars on the graph indicate the volume of data seen over the reporting period, by default 2 hours.
Summary Interfaces
This is a graph and table of interface bit rates, with a breakdown by individual interface. This is a summary of the busiest interfaces across your network.
See Configuration > Infrastructure Devices for setup instructions.
When more than 10 devices are registered, the full list can be displayed by clicking List All Drill down icon. beside the table title.
The CSV link at the top right of the table generates a .csv export.
Events
This middle graph shows all events and alerts across your network during the reporting period.
Reporting Period
Figure: Detail of GigaFlow's report period selection panel, at the top of most pages

- The reporting period is shown at the top right of the main body of the page. This is 2 hours by default.
- On login, the system displays information for the default time period.
- This default time period can be set in Configuration > Reporting in the main menu.
- Different reporting periods can be selected by clicking the from and to boxes.
Figure: Clicking in either the From or To field brings up a date and time selector.

Device and Interface Overview
Click once on any infrastructure device IP address or interface in the tables and you will be taken to an overview report for that device or interface. You can access the same overview using GigaFlow's search function. Search for the IP address and in the main left-hand side table, click the Infrastructure Device name. In the right-hand side table, click Overview.
See Dashboards > Device Overview and Dashboards > Interface Overview.
Device Overview
Located at Dashboards > Device Overview; there is also a unique Device Overview subpage for each infrastructure device.
From the Dashboards menu, the Device Overview option displays:
- Busiest devices in the past hour.
- Summary devices.
This information is also displayed in Performance Overview and in Server Overview. See Dashboards > Performance Overview > Top Devices (Last Hour v Last Week Hour) and Dashboards > Server Overview.
Device Overview Subpages
Click once on any infrastructure device IP address or interface in the tables and you will be taken to an overview report for that device or interface. You can access the same overview using GigaFlow's search function. Search for the IP address and in the main left-hand side table, click the Infrastructure Device name. In the right-hand side table, click Overview.
The overview for each infrastructure device includes graphs and tables with useful information. These include:
Device Details
This panel lists the most important device information, including:
- IP address.
- Display name.
- SysName.
- SysLocation.
- SNMP status.
- ARP entries.
- CAM entries.
- System description.
Attributes and Tools
You can add an Attribute, or alias, for network infrastructure by selecting from the interface Attributes drop down selector. See Configuration > Attributes for more on attributes. This panel lists attributes and useful tools associated with the selected device, including:
Attributes. See Configuration > Infrastructure Devices and click on any device for more. Links out to useful tools, including Forensics, ARPs, CAMs, Live Interfaces and Traffic Overview. Links to associated integrations. See System > Global for more about integrations.
Top 10 Applications This Hour
Figure: Visual from Device Overview subpage

The information is presented as a pie-chart. Each application can be queried by clicking the drill down icon for more.
This graph shows the top 10 ports/applications associated with this device in the past hour.
Top 10 Site Pairs This Hour
This graph shows the top 10 site pairs associated with this device in the past hour.
Top 10 Source IPs This Hour
This graph shows the top 10 source IPs associated with this device in the past hour.
Top 10 Destination IPs This Hour
This graph shows the top 10 destination IPs associated with this device in the past hour.
Summary Devices
This graph shows the summary traffic volume information for this device (MB/s).
Summary Interfaces
This graph shows the summary interface traffic volume information for this device (MB/s).
Events Graph
A timeline of threat events associated with the device in the report period.
A table of all the interfaces associated with this device is displayed at the bottom of the page; the information presented includes:
All Interfaces CSV
- The device name.
- The ifIndex of the interface.
- The name of the interface.
- A description of the interface.
- Any alias given by the local user.
- The IP address associated with the interface.
- The nominal inward flow rate (MB/s), defined by the user.
- The nominal outward flow rate (MB/s), defined by the user.
- The average inward flow rate as a percentage of the nominal inward flow rate.
- The average inward flow rate (MB/s).
- The maximum inward flow rate as a percentage of the nominal inward flow rate.
- The maximum inward flow rate (MB/s).
- The average outward flow rate as a percentage of the nominal outward flow rate.
- The average inward flow rate (MB/s).
- The maximum outward flow rate as a percentage of the nominal outward flow rate.
- The maximum outward flow rate (MB/s).
Interface Overview
Located at Dashboards > Interface Overview; there is also a unique Interface Overview subpage for each interface.
From the Dashboards menu, the Interface Overview option displays high-level summary information; some of this is also displayed in Server Overview. See Dashboards > Server Overview. The three graphs displayed are:
- Top Interfaces In (Last Hour v Last Week Hour), i.e. the interfaces with heaviest inward traffic over the past hour. This is compared to the same hour last week.
- Top Interfaces Out (Last Hour v Last Week Hour), i.e. the interfaces with heaviest outward traffic over the past hour. This is compared to the same hour last week.
- Summary Interfaces.
- Summary Interfaces Peak.
Figure: GigaFlow's Interface Overview page

Click once on any infrastructure device IP address or interface in the tables and you will be taken to an overview report for that device or interface. You can access the same overview using GigaFlow's search function. Search for the IP address and in the main left-hand side table, click the Infrastructure Device name. In the right-hand side table, click Overview.
Dedicated Interface Overview Pages
At the top of the page, you can see:
Interface Details
This panel displays the interface details:
- IfIndex: the interface number.
- The interface name.
- The interface alias.
- The interface description.
- The interface IP address.
- The interface MAC address.
- Speed In (MB/s).
- Speed Out (MB/s).
- Admin status.
- Oper status.
You can edit these at Configuration > Infrastructure Devices.
Attributes and Tools
You can add an Attribute, or alias, for an interface by selecting from the interface Attributes drop down selector. See Configuration > Attributes for more. This panel lists attributes and useful tools associated with the selected interface, including:
- Attributes.
- Links out to useful tools, including Forensics, ARPs, CAMs, Live Interfaces and Traffic Overview.
- Links to associated integrations. See System > Global for more about integrations.
In addition, you will see graphs and tables of:
Summary Interface Total Traffic
This is a summary of the total traffic for that interface.
Summary Interface In
This is a summary of the total inward traffic for that interface.
Summary Interface Out
This is a summary of the total outward traffic for that interface.
Summary Interface In Packets
This is a summary of the total inward packets for that interface.
Summary Interface Out Packets
This is a summary of the total outward packets for that interface.
Summary Interface In Flows
A summary of the total inward flows for that interface.
Summary Interface Out Flows
This is a summary of the total outward flows for that interface.
Summary Interface DSCP In Ingress Bytes
DSCP (differentiated services code point) in summary information used for ingress policing configuration.
Summary Interface DSCP Out Ingress Bytes
DSCP (differentiated services code point) out summary information used for ingress policing configuration.
Summary Interface DSCP In Egress Bytes
DSCP (differentiated services code point) in summary information used for egress policing configuration.
Summary Interface DSCP Out Egress Bytes
DSCP (differentiated services code point) out summary information used for egress policing configuration.
Application Overview
Application traffic overview.
Top Applications (Last Hour v Last Week Hour)
This graph shows the traffic associated with the busiest applications over the past hour. The information displayed includes:
- Avg Bits/s: average traffic per second per application.
- Percentage: this is the proportion of all traffic over the past hour seen by a particular application.
- Position relative to the same hour last week: this is the percentage increase or decrease in traffic per second per application compared with the same hour last week.
When more than ten applications are registered, the full list can be displayed by clicking the drill down icon. This displays a tabular version of all the data, with a CSV export option.
Top Source Addresses (Last Hour v Last Week Hour)
This graph shows the top 10 source IPs over the past hour; this is compared with the same hour a week before.
Top Destination Addresses (Last Hour v Last Week Hour)
This graph shows the top 10 destination IPs over the past hour; this is compared with the same hour a week before.
Summary Traffic Applications
This is a graph and table of site bit rates, with a breakdown by individual site. This is a summary of the busiest sites across your network.
See Configuration > Sites for setup instructions.
When more than 10 sites are registered, the full list can be displayed by clicking List All Drill down icon. beside the table title.
The CSV link at the top right of the table generates a .csv export.
Source IP Overview
This section provides an overview of the traffic associated with source IPs.
Top Applications (Last Hour v Last Week Hour)
This graph shows the traffic associated with the busiest applications over the past hour. The information displayed includes:
- Avg Bits/s: average traffic per second per application.
- Percentage: this is the proportion of all traffic over the past hour seen by a particular application.
- Position relative to the same hour last week: this is the percentage increase or decrease in traffic per second per application compared with the same hour last week.
When more than ten applications are registered, the full list can be displayed by clicking the drill down icon. This displays a tabular version of all the data, with a CSV export option.
Top Source Addresses (Last Hour v Last Week Hour)
This graph shows the top 10 destination IPs over the past hour.
Top Destination Addresses (Last Hour v Last Week Hour)
This graph shows the top 10 destination IPs over the past hour.
Summary Traffic Source IPs
This is a graph and table of traffic source IP bit rates, with a breakdown by individual site. This is a summary of the busiest traffic source IPs across your network.
When more than 10 traffic source IPs are registered, the full list can be displayed by clicking List All Drill down icon. beside the table title.
The CSV link at the top right of the table generates a .csv export.
Destination IP Overview
This section provides an overview of the traffic associated with destination IPs.
Top Applications (Last Hour v Last Week Hour)
This graph shows the traffic associated with the busiest applications over the past hour. The information displayed includes:
- Avg Bits/s: average traffic per second per application.
- Percentage: this is the proportion of all traffic over the past hour seen by a particular application.
- Position relative to the same hour last week: this is the percentage increase or decrease in traffic per second per application compared with the same hour last week.
When more than ten applications are registered, the full list can be displayed by clicking the drill down icon. This displays a tabular version of all the data, with a CSV export option.
Top Source Addresses (Last Hour v Last Week Hour)
This graph shows the top 10 source IPs over the past hour.
Top Destination Addresses (Last Hour v Last Week Hour)
This graph shows the top 10 destination IPs over the past hour.
Summary Traffic Destination IPs
This is a graph and table of traffic destination IP bit rates, with a breakdown by individual site. This is a summary of the busiest traffic destination IPs across your network.
When more than 10 traffic destination IPs are registered, the full list can be displayed by clicking List All Drill down icon. beside the table title.
The CSV link at the top right of the table generates a .csv export.
Sites Overview
Located at Dashboards > Sites Overview; there is also a unique Sites Overview subpage for each site.
From the Dashboards menu, the Sites option displays summary information.
Sites Subpages
Click once on any Sites name in the table and you will be taken to an overview report for that site.
Click once on any of the "Down Arrows" beside the site name in the table and you will be taken to the forensics report for that site.
The overview for each site includes graphs and tables with useful information (similar to device overviews). These include:
Top Sites Sources (Last Hour v Last Week Hour)
This graph shows the top 10 destination IPs over the past hour.
Top Sites Destinations (Last Hour v Last Week Hour)
This graph shows the top 10 destination IPs over the past hour.
Top Sites Sources (Last Hour v Week Last Week Hour)
This graph shows the top 10 source IPs over the past hour.
Top Sites Destinations (Last Hour v Week Last Week Hour)
This graph shows the top 10 destination IPs over the past hour.
Summary Source Sites
This graph shows the source traffic associated with sites over the past hour. The information displayed includes:
- Avg Bits/s: average traffic per second per application.
- Percentage: this is the proportion of all traffic over the past hour seen by a particular site.
- Position relative to the same hour last week: this is the percentage increase or decrease in traffic per second per site compared with the same hour last week.
When more than ten sites are registered, the full list can be displayed by clicking the drill down icon. This displays a tabular version of all the data, with a CSV export option.
Summary Destination Sites
This graph shows the destination traffic associated with sites over the past hour. The information displayed includes:
- Avg Bits/s: average traffic per second per application.
- Percentage: this is the proportion of all traffic over the past hour seen by a particular site.
- Position relative to the same hour last week: this is the percentage increase or decrease in traffic per second per site compared with the same hour last week.
When more than ten site are registered, the full list can be displayed by clicking the drill down icon. This displays a tabular version of all the data, with a CSV export option.
Events
Located at Dashboards > Events.
From the Dashboards menu, the Events option displays summary information about events and exceptions. See also Dashboards > Server Overview. You can also click on Events item in the main menu to access the same information.
Some things that will trigger an event record include:
- Attempts to access blacklisted resources.
- Profile exceptions, i.e. behaviours deviating from norms. These are user defined at Configuration > Profiling.
- SYN flood event(s).
- Lost neighbour(s).
- New device(s) sending flows.
- Connected device(s) suddenly not sending flows.
On the Events page, you can see:
A timeline of all events in the reporting period, the Events Graph. A tabulated version of this information is shown underneath.
Figure: Events Graph
- Infographic of the number of event types by date and time; this is the Event Types infographic. Circle size indicates the number of events.
- Infographic of the frequency of occurence of particular event categories by date and time, i.e. number of times per time interval; this is the Event Categories infographic. Circle size indicates frequency.
- Infographic of the frequency of an event triggered by a particular source host by date and time; this is the Event Source Host(s) infographic. Circle size indicates frequency.
- Infographic of the frequency of an event targetted at a particular host by date and time, i.e. number of times per time interval; this is the Event Target Host(s) infographic. Circle size indicates frequency.
Figure: Event Categories infographic
- Infographic of the frequency with which each infrastructure device was affected by an event by date and time, i.e. number of times per time interval; this is the Infrastructure Devices infographic. Circle size indicates frequency.
- Infographic of the frequency of an event by the measure of confidence in its identification, i.e. your confidence in the completeness and accuracy of the blacklist that the IP address was found in, and the severity of the threat to your network infrastructure, i.e. number of times per time interval; this is the Confidence & Severity infographic. Circle size indicates frequency.
Figure: Confidence & Severity infographic
By clicking once on any legend item, you will be taken to a detailed report, e.g. detailed reports for each Event Type, Source Host, Infrastructure Device, Event Category and Target Host.
Threat Map
To view a world map overlaid with attack/event trajectories, click on the Threat Map main menu item.
- Select the report period using the Window pull-down menu, e.g. select 12 hours to view threat data for the past 12 hours.
- A timeline above the main map displays threats during the report period.
- Threat trajectories are displayed on the main map in the centre of the screen.
Figure: The main threat map visualization

Alongside the map, you will see the expandable tables:
- Threat Src Locations: a list of the countries where the threats originate.
- Event IP Sources: a list of the IPs associated with the threats.
- Event Types: a list of the types of threat identified .
- Event Categories: a list of the threat categories.
- Event Devices: a list of your infrastructure devices involved in the threat.
- Threat Dest Locations: a list of the countries where devices affected by the threats reside.
- Event IP Dests: a list of the IP addresses affected by the threats, i.e. where did the data go.
Most items in the side tables can be examined in isolation, i.e. Event IP Sources, Event Types, Event Categories, Event Devices, Event IP Destinations.
- To focus on a single event IP source:
Click on the relevant IP and the page will display information related only to that IP. The main table below the map displays a complete summary of the the threats mapped with time. In addition to the information presented in the side tables, the main table includes:
- The protocol/application involved.
- The byte-size of the threat event.
- The number of packets involved in the threat event.
Events (Main)
See Dashboards > Events.
Profiling
The Profiling main menu item has three options: Realtime Overview, Event Dashboard and Sites.
Profiles help you to understand the normal behaviour of your network. For more, and to create profiles, go to Configuration > Profiling.
Realtime Overview
Profiling > Realtime Overview
The Realtime Profiling Status shows realtime data on defined Profilers. The display updates every 5 seconds and shows:
- Profiler: this is the defined profile.
- Clients: the number of connected devices.
- Hits: the number of flow records that have matched the allowed flows.
- Exceptions: the flow records for this profile that have deviated from the ideal, or Allowed, profile. See Configuration > Profiling.
Profiling Events
Located at Profiling > Profiling Events.
The Profiling Event Dashboard gives an overview of profile events.
Figure: The Profiling Events page

Reporting Period
At the top of the page you can set both the reporting period and resolution, from one minute to 4 weeks.
Profiles
This infographic shows a timeline of the number of events with the profile(s) involved. Circle diameters represent the number of events. The peak number of events in the timeline for each profile are highlighted in red.
Severities
This infographic shows a timeline of the number of events along with their estimated severity level(s). Circle diameters represent the number of events. The peak number of events in the timeline for each severity level are highlighted in red.
Event Entries
Event Entries is dynamically generated; you must click Click To Load to populate the table. The Event Entries table gives a breakdown of profile events with the following entries:
- The unique event ID number.
- The time at which event occurred.
- The category or profile name.
- The severity of the event as a percentage.
- The source IP address.
- The target IP address.
- The application, user defined if it exists. See also Configuration > Profiling and Flow Details.
- Any information other error/status message, e.g. Profiler Exception.
A drop-down selector lets you choose the number of the most events to display.
Flow Details
To access a detailed overview of any flow, click on the adjacent Drill Down icon ![]() . This provides a complete overview of that flow, listing:
. This provides a complete overview of that flow, listing:
- The source address, a link to search forensics and any associated blacklists.
- Source MAC address.
- Destination address, a link to search forensics and any associated blacklists.
- Destination MAC address.
- Source port.
- Destination port.
- Appid: the application ID is a unique identifier for each application.
- In GigaFlow, Appid is a positive or negative integer value. The way in which the Appid is generated depends on which of the 3 ways the application is defined within the system. Following the hierarchy outlined in Configuration > Profiling -- Apps/Options -- Defined Applications, a negative unique integer value is assigned if (1) the application is associated with a Profile Object or (2) if it is named in the system. If the application is given by its port number only (3), a unique positive integer value is generated that is a function of the lowest port number and the IP protocol.
- Application. See Appid, above, and Configuration > Profiling.
- Number of packets in flow.
- Number of bytes.
- User.
- Domain.
- Fwevent. See
- Fwextcode.
- Profile, e.g. PCs.
- Net device IP address, name and number of flows.
- In-Interface.
- Out-Interface.
See Glossary for more about flow record fields used by GigaFlow.
See also Search for instructions to access the Graphical Flow Mapping feature.
Filtered Views
By clicking any Category, Severity, Source IP or Target IP in the Event Entries table, you will be taken to a version of the Events Dashboard filtered for that item.
See Dashboards > Events for an overview of the structure of this page.
(Existing) Sites
Overview
Located at Profiling > Sites.
Sites are subnet and IP range aliases.
- You can assign a name to a subnet or IP range.
- GigaFlow will collect data associated with this range.
- A site can be a subset of another site, e.g. a site spans 172.1.1.0 - 172.1.1.255 and a second site is defined as 172.1.1.80 - 172.1.1.122.
Top Sites Sources (Last Hour v Last Week Hour)
This graph shows the top 10 destination IPs over the past hour.
Top Sites Destinations (Last Hour v Last Week Hour)
This graph shows the top 10 destination IPs over the past hour.
Top Sites Sources (Last Hour v Week Last Week Hour)
This graph shows the top 10 source IPs over the past hour.
Top Sites Destinations (Last Hour v Week Last Week Hour)
This graph shows the top 10 destination IPs over the past hour.
Summary Source Sites
This graph shows the traffic associated with sites over the past hour. The information displayed includes:
- Avg Bits/s: average traffic per second per application.
- Percentage: this is the proportion of all traffic over the past hour seen by a particular site.
- Position relative to the same hour last week: this is the percentage increase or decrease in traffic per second per site compared with the same hour last week.
When more than ten site are registered, the full list can be displayed by clicking the drill down icon. This displays a tabular version of all the data, with a CSV export option.
Summary Destination Sites
This graph shows the destination traffic associated with sites over the past hour. The information displayed includes:
- Avg Bits/s: average traffic per second per application.
- Percentage: this is the proportion of all traffic over the past hour seen by a particular site.
- Position relative to the same hour last week: this is the percentage increase or decrease in traffic per second per site compared with the same hour last week.
When more than ten sites are registered, the full list can be displayed by clicking the drill down icon. This displays a tabular version of all the data, with a CSV export option.
Reports
Reports gives you access to system reports and logs. GigaFlow stores a record of all reports. Reports can be generated in many ways but most commonly by viewing a Forensics page; viewing a Forensics page automatically generates a report. When a report is generated by a user, it is cached by the system and can be accessed again almost immediately. In addition, all recorded reports can be re-run from scratch at any time. Runtimes vary with the scope of the report, i.e. reports that involve more data will take longer to complete. Typical reports for limited periods of time complete in seconds.
Administrators have access to all reports run by all users.
See Configuration > Reporting for more.
My Current Queries
Located at Reports > My Current Queries.
My Current Queries lists your queries currently in process. The table includes:
- The user that initiated the report.
- Report source, e.g. Forensics. See Reports > Forensics.
- Report type, e.g. Application. See Forensic Report Types in the appendix.
- Output type, i.e. graph or table.
- When the report was started.
- Runtime.
- Size in bytes.
- Actions: view the cached report or re-run the report from scratch.
The filters used to define the report.
My Complete Queries
Located at Reports > My Complete Queries.
My Complete Queries lists your completed queries. The table includes:
- The user that initiated the report.
- Source, e.g. Forensics. See Reports > Forensics.
- Report type, e.g. Application. See Forensic Report Types in the appendix.
- Output type, i.e. graph or table.
- When the report was started.
- Runtime.
- Size in bytes.
- Actions: view the cached report or re-run the report from scratch.
- The filters used to define the report.
All Complete Queries
Located at Reports > All Complete Queries.
This option provides administrators with a view of all queries made by all users.
- The user that initiated the report.
- Source, e.g. Forensics. See Reports > Forensics.
- Report type, e.g. Application. See Forensic Report Types in the appendix.
- Output type, i.e. graph or table.
- When the report was started.
- Runtime.
- Size in bytes.
- Actions: view the cached report or re-run the report from scratch.
- The filters used to define the report.
All Current Forensics
This option provides administrators with a view of all forensic queries made by all users.
Running Requests
- MyID:
- User: The user that initiated the report.
- Source: Forensics. See Reports > Forensics.
- Report: Report type, e.g. Application. See Forensic Report Types in the appendix.
- Output: Output type, i.e. graph or table.
- Started At: When the report was started.
- Running For: Runtime, so far.
- Request:
Canceled Queries
Located at Reports > Canceled Queries.
Canceled Queries lists your canceled queries. The table includes:
- Source, e.g. Forensics. See Reports > Forensics.
- Report type, e.g. Application. See Forensic Report Types in the appendix.
- Output type, i.e. graph or table.
- When the report was started.
- Runtime.
- The reason for canceling the report.
- The filters used to define the report.
Cluster Search
Located at Reports > Cluster Search.
Figure: Conducting a GigaFlow Cluster search
[file: Conducting a GigaFlow Cluster search.]
Following the search link from Apex, you will be brought to a new tab and the log in screen for the Pitcher machine. After logging in, you will be brought to the GigaFlow Cluster report page.
Figure: The initial view of the GigaFlow Cluster report page
This displays a list of hits for this IP address across the cluster; in this example, the IP address 172.21.21.21 was found on 11 devices monitored by three receivers. On these receivers the system found 9 devices with data matching the search and there were no errors.
In the first first table, each GigaFlow server is listed with:
- Server name.
- The URL to connect to the server; follow this link to access the full UI for that particular server.
- The type of result; in this case flows.
- Which device monitored by this server had the data.
- Device details: name, interface and the number of flows seen.
- A number and visualization of the data size; this is a ranking of result relevance.
- A drill-down link to forensics data for each result. A full view into the receiver is displayed below the top table; this allows you to view the results and interact with that GigaFlow server without having to leave this page.
Figure: Clicking on the drill down icon beside a result brings up the full user interface and a forensics report for that device on the associated GigaFlow server
The system allows ten minutes between running the report and viewing these results without re-authentication.
You can also select different report types to run on that device on that GigaFlow server by selecting from the drop-down menu. See Reports > Forensics in the main Reference Manual for more.
DB Queries
Located at Reports > DB Queries.
DB Queries displays a list of the most recent database queries. The information returned includes:
- The database accessed.
- The client requesting the query.
- The start time.
- The query duration.
- Wait events.
- Process ID.
- Query performed.
Forensics
Located at Reports > Forensics.
See Configuration > Reporting for instructions on how to configure and create new report types. See Appendix > Forensic Report Types for a complete description of the different report types.
Forensics allows you granular, filterable reporting on the stored records. GigaFlow records flow posture, i.e. whether or not a flow is flagged as an excepted event, allowing for detailed analysis.
To create a report:
- Select a report type from the drop-down menu.
- Apply filters to the records to customize output.
- Multiple filters can be selected from the drop-down menu.
- Filters can also be entered using GigaFlow's Direct Filtering Syntax (see below).
- Select the Reporting Period.
- Choose the output type, i.e. graph or table, from the drop-down menu.
- Click on Save if you want to keep your report.
Example
A router - an infrastructure device - has an IP of 192.0.2.1. This router was defined at Configuration > Infrastructure Devices. Choose an Applications report from the report type drop-down menu. Choose Infrastructure Device from the filter drop-down menu. Choose the router from the list of devices and apply the filter by clicking +.
The system will return a graph and/or table with details of:
- Source IP.
- Destination IP.
- Application.
- Bit rate and/or total bits.
Reporting Period
- The reporting period is shown at the top right of the main body of the page. This is 2 hours by default.
- On login, the system displays information for the default time period.
- This default time period can be set in Configuration > Reporting in the main menu.
- Different reporting periods can be selected by clicking the from and to boxes.
Direct Filtering Syntax
Queries can be entered directly and quickly using the direct filtering syntax.
| Field | Operators | Description | Example |
|---|---|---|---|
| srcadd | =, != | IP Address that the traffic came from. | srcadd=172.21.40.2 |
| dstadd | =, != | IP Address that the traffic went to. | dstadd=172.21.40.3 |
| inif | <, =, >, != | ifIndex of the interface through which the traffic came into the router. | inif=23 |
| outif | <, =, >, != | ifIndex of the interface through which the traffic left the router. | inif=25 |
| pkts | <, =, >, != | Number of packets seen in the flow. | pkts>100 |
| bytes | <, =, >, != | Number of bytes seen in the flow. | bytes<10000 |
| duration | <, =, >, != | Duration of flow in milliseconds. | duration>100 |
| srcport | <, =, >, != | Source IP port of flow. | srcport>1024 |
| dstport | <, =, >, != | Destination IP port of flow. | dstport=5900 |
| flags | <, =, >, != | TCP Flags of flow. flags=2 i.e. syn only. | Flags=CEUAPRSF |
| proto | <, =, >, != | IP Protocol Number/Type. | proto=16 |
| tos | <, =, >, != | TOS Marking. tos=104 | //Flash |
| srcas | <, =, >, != | Source AS Number. | srcas!=5124 |
| dstas | <, =, >, != | Destination AS Number. | dstas!=5124 |
| fwextcode | =, != | Forwarding Extended Code. | fwextcode='out-of-memory' |
| fwevent | =, != | Forwarding Event. | fwevent!='Flow Deleted' |
| tgsource | =, <> | Site Source. | fwextcode<>'My network 1' |
| tgdest | =, <> | Site Destination. | tgdest<>'Other' |
- Ranges are also supported for IP address, port and AS fields. i.e. "dstport in (22,23,80,443) will match any flow where the dstport is either of the specified ports.
- Logical operators "and", "or", "not" as well as parentheses can also be used. i.e. "dstport not in(23,2055,443) and srcport not in (8585,23) and (fpr > 0 or pkts < 100)".
- It is possible to check the bit value of a field using the bitand function i.e. "(flags bitand 4)=4" filters for flows with the Reset flag set.
First Packet Response
Located at Reports > First Packet Response.
First Packet Response (FPR) is a useful diagnostic tool, allowing you to compare the difference between the first packet time-stamp of a request flow and the first packet time-stamp of the corresponding response flow from a server. By comparing the FPR of a transaction with historical data, you can troubleshoot unusual application performance.
Monitored Servers
On loading, this page displays any First Packet Response information available for Monitored Servers.
Figure: The First Packet Response reports page

To set up a monitored server, go to Configuration > Server Subnets.
The displayed information includes:
- Device IP address.
- Server subnet.
- Port number.
- Number of clients.
- Number of flows.
- Time and date last seen.
- Basic statistics.
Monitored Infrastructure Devices/Servers/Ports
On loading, this page displays any First Packet Response information available for Monitored Servers.
Figure: The First Packet Response reports page

To set up a monitored server, go to Configuration > Server Subnets.
The displayed information includes:
- Device IP address.
- Server subnet.
- Port number.
- Number monitored clients.
- Number of flows, maximum number of clients.
- Maximum number of flows per minute.
- Minimum response time.
- Average response time.
Ticker Table

Click the Ticker check box next to a device to enable a ticker in the table below with live response times in milliseconds.
Ip Viewer
GigaFlow's Ip Viewer uses MapBox to visualise the physical location of IP addresses
- User:
- Device:
- IP:
- Switch:
- Router:
- Bandwidth:
- Apps:
- Bandwidth:
- Hosts:
NAT Reporting
The NAT Reporting dialog shows network translations that are color coded in order for you to easily identify which entries changed for each session. The colors indicate that the NAT process has changed that value. Each value type has a different color to make the changes obvious. For example, a value found in the dark-green color under the NAT SRCADD column represents the translated network address of the value found in the same row under the SRCADD column with the same color.

If you want the NAT report to be focused on a particular time period, then click the Pick period drop-down box in the upper-right corner of the dialog. Here you can customize the time period according to different criteria (for example, Last, This, To Date, or Trailing).
In the upper-left corner search boxes, you can perform the following types of searches:
- In the first box you can select a specific device or all the devices to search for their records.
- In the Search IP/UserID and/or Search IP (Optional) boxes you can serch records for an IP Address, a UserID, a UserID + an IP Address, or an IP Address Pair.
If you want to remove/show the duplicate records, then click the Show/Hide Duplicates button.
If you click the Show Only Translated/Show All 1000 button, then only the records that were changed by the NAT process are shown or all the records respectively.
The lens icon related to the DEVICE column tries to find that same session on other devices on the GigaFlow server.
The drill-down arrow related to the DEVICE column redirect you to the Reports > Forensics dialog for that Session ID on that specific device.
The drill-down arrows related to the NAT SRCADD and NAT DSTADD columns redirect you to Reports > IP Viewer. The IP Viewer modal provides the ability to search for an IP address or user data across multiple GigaFlow servers and routers in an organization without having to know anything about that organizations network infrastructure. The IP Viewer modal displays the found data in a simple and accessible way to the end user, while providing filtering and drill-down capabilities right down to the raw forensics level.
You can also find the NAT devices in the Configuration > Infrastructure Devices dialog. Here you can see all the devices that GigaFlow is receiving NAT data for. If the Nat column is marked as true, then the related device is available in the NAT Reporting dialog.
Network Audits
A network audit report is a standard-format JSON object that contains a summary of all the devices registered by GigaFlow that belong to a particular subnet.
Network audit reports are enabled for a particular subnet at Reports > System Wide Reports > Subnet List. Enabling a network audit runs the network audit script for the selected subnet(s). You can view the network audit script at System > Event Scripts.
Server configuration happens at Configuration > Server Subnets.
Saved Reports
Located at Reports > Saved Reports.
Newly generated reports of interest can be saved for reference. Click Save ![]() in the top right corner.
in the top right corner.
Once a report has been saved it can be viewed in two ways: (i) open. This opens without running. More filters can be added; (ii) open and run.
Saved Reports are listed with the following information:
- Who created the report.
- Where the report originated, e.g. Forensics.
- Report type.
- Report name.
- Action.
- Description.
- Additional filtering.
- When it was created.
Server Discovery
Server Discovery By Device
Each automatically discovered server is listed here with:
- Device: this is the IP address of the server.
- Capacity:
- Src Monitored Sessions:
- Src Threshold:
- Dst Monitored Sessions:
- Dst Threshold:
Clicking on a device brings up detailed information for that server.
Server Discovery/Detailed Information
Details about each discovered server are shown here, with information about its behaviour as a source and destination for traffic. Two tables are shown on screen.
Servers As Source
- IP: IP address
- Port:
- Application:
- Flows:
Servers As Destination
- IP:
- Port:
- Application:
- Flows:
System Wide Reports
Located at Reports > System Wide Reports.
These are static reports produced by GigaFlow. From the Reports menu, the System Wide Reports option expands to display a further five options:
- SYN Forensics Monitoring
- Device Connections
- MAC Address Vendors
- Subnet List
- Flow Stats
SYN Forensics Monitoring
Located at Reports > System Wide Reports > SYN Forensics Monitoring.
GigaFlow monitors all TCP flows where only the SYN bit is set. In normal network operations, this indicates that a flow has not seen a reply packet while active in a router's Netflow cache.
A lonely SYN can be an indicator that:
- Routing was asymmetric. Perhaps the reply returned via a different router.
- Reply traffic was blocked.
- Servers were not responding for some reason.
- Something was probing the network.
GigaFlow creates an alert when:
- SYN Source Network Sweep: alerts if a source IP address fails to get a response from more than IP Address Count Threshold unique destination addresses.
- SYN Source Port Sweep: alerts if a source IP address fails to get a response from more than Port Count Threshold unique destination ports.
- SYN Source Network And Port Sweep: alerts if a source IP address exceeds both Port Count Threshold and IP Address Count Threshold thresholds.
- SYN Destination Unreachable Server: alerts if a destination IP address fails to respond to more than IP Address Count Threshold unique destination addresses.
- SYN Destination Port Sweep: alerts if a destination IP address fails to respond to more than Port Count Threshold unique destination ports.
- SYN Destination Network And Port Sweep: alerts if a destination IP address exceeds both Port Count Threshold and IP Address Count Threshold.
On the SYN Forensics Monitoring page, you can find two tables of information:
- SYN Sources.
- SYN Destinations.
Each table lists the following information:
- Source or destination IP addresses.
- The number of destinations or sources.
- The number of destination ports.
- The number of flows.
- The type of SYN, e.g. network sweep.
- When it was first seen.
- When it was last seen.
See also System > Alerting
Device Connections
Located at Reports > System Wide Reports > Device Connections.
This page lists all known network connected devices. This list is used as a look-up for Layer-2 to Layer-3 connectivity.
The table lists:
- Device.
- Device name.
- Interface.
- Interface name.
- VLAN.
- VLAN ID.
- MAC address.
- IP address.
- User
- MAC vendor.
Clicking the export icon beside the page title creates a .csv file for download or printing.
MAC Address Vendors
Located at Reports > System Wide Reports > MAC Address Vendors
This page shows information about devices associated with particular MAC vendors on your network; GigaFlow displays:
- The MAC vendor name.
- The number of times devices from that vendor has been seen, Count.
Click on Count to populate the second table, MAC Addresses. These are the individual devices associated with that vendor. For each device, the table shows:
- Device MAC address.
- When it was last seen on Layer-2.
- When it was last seen on Layer-3.
Subnet List
The Subnet List report summarises all the subnets automatically discovered using SNMP. The details listed are:
- Device Name: the server name.
- Device IP: the server IP address.
- IfIndex: the interface index.
- Name: the interface name.
- Subnet IP: the subnet IP address.
- Subnet: the subnet name.
- Mask: the subnet mask.
- Alias: the subnet alias.
- Description: the subnet description.
- Speed In: the inward bit rate (MB/s).
- Speed Out: the outward bit rate (MB/s).
- Admin: admin status.
- Oper: oper status.
- Audit: audit status.
Flow Stats
This report summarises infrastructure devices by flow rate, showing a graph and table listing, for each device:
- Device name and IP address.
- Flow rate (flows per second) and total flows over the report period.
- The maximum flow rate and time it occurred.
- The percentage of the total number of flows over the report period contributed by this device.
SQL Reports
Located at Reports > SQL Report.
Select how many of the most recent SQL Queries to view from the drop-down menu, i.e. the most recent 10, 50, 100 or All.
The table lists the following information:
- Query ID.
- Date created.
- User that created the query.
- Name of the query.
- What the query was.
Working with SQL Queries
- To run the report with a HTML output, click HTML.
- To run the report with a .csv output, click CSV.
- Click Edit
 to modify the report.
to modify the report. - Click Remove
 to remove the report.
to remove the report.
Adding a SQL Query
- To add a SQL report, enter a name and then Save .
- The new report will appear in the SQL Report Filters Table.
- Click Edit to open and modify the report.
Trace Extraction Jobs
Located at Reports > Trace Extraction Jobs.
This report gives details on the trace extraction jobs that you have created, such as creation date, completion status, file size, start time, end time, applied filter.

You can take the following actions on the generated package capture files:
- Download: click the
 icon next to the file name to download it on your machine.
icon next to the file name to download it on your machine. - Delete: click the
 icon next to the file name to delete it.
icon next to the file name to delete it.
User Events
Located at Reports > User Events.
Select how many of the most recent User Events to view, i.e. the most recent 50, 100, 250 or 500 events.
This table gives information about:
- Event date/time.
- User requesting the event, if you are logged in as an administrator.
- Source IP address.
- Category of event, e.g. a login or a report.
- The action or function performed.
- JSON parameters.
Configuration
Figure: The Configuration menu

Applications
GigaFlow comes loaded with a standard set of application port and protocol definitions. Flow records are associated with application names if there is a match.
Users can define their own application names within the software and have that application ID (Appid) available within the flow record. There are 3 techniques used, applied in order:
- Customers can define an application profile which lets them match traffic by source/destination IP address, source/destination port, source/destinaton MAC address, protocol, COS and/or nested rules.
- They can assign their own application names to specificed IP ports, i.e. create Named Applications.
- Or, if there are no user defined settings, the software will select the lowest port.
Add Defined Service
To add a defined service, perform the following steps:
- In the GigaFlow UI, go to the Configuration > Applications page.
- In the upper-right corner, click the Add Defined Service
 button.
button.
The NEW DEFINED SERVICE dialog shows.
- In the Name field, enter the name of the service you want to add.
Possible values: alphanumeric ASCII characters string
Default setting: empty field - In the Description field, enter a description for the service.
Possible values: alphanumeric ASCII characters string
Default setting: empty field - In the IP Addressing field, enter the server IP address(es).
Possible values: IPv4 and/or IPv6 addresses
Format: individualIP addresses separated by commas, and/orIP address ranges (IP_Start-IP_End) , and/orIP/Mask , and/orIP/Mask Length
Example:172.21.40.5, 172.21.40.6-172.21.40.28, 192.168.0.1/24
Default setting: empty field - In the IP Port(s) field, enter the server port(s).
Possible values:1..65535 (integer)
Format: individualPort numbers separated by commas, and/orPort ranges
Example:43, 137-139, 23
Default setting: empty field - In the Protocol drop-down list, select the transport protocol that you want to use.
Possible values: TCP, UDP, SCTP
Default value: Any - Click the Save button.
The Name field and at least one of the IP Addressing or IP Port(s) fields are mandatory. The Description and the Protocol fields are optional. |
Add Defined Application
- In the New Defined Application section, specify a name, a description and select the flow object that is associated with the application.
- Click Save to add the application.
Add Flow Object
- Specify the flows that make up the object.
Flow Objects are defined by:
- Name.
- Description.
- Device IP address (Device IP).
- Source IP address (Src IP).
- Source MAC address (Src MAC).
- Source Port (Src Port).
- Source Site.
- Destination IP address (Dst IP).
- Destination MAC address (Dst MAC).
- Destination Port (Dst Port).
- Destination Site.
- Protocol.
- Class of Service (COS).
- Negate (True/False)
IP addresses, MAC addresses, Ports and Sites can also be defined as both Source/Destination.
You can add ANDd existing profile(s) to the new Flow Object, i.e. the new definitions are added to the existing profile(s).
You can also select alternative existing profile(s) that this new profile also maps to (ORd), i.e. the new Flow Object uses either the new definitions or the existing Flow Object definitions.
To ANDd or ORd profile(s), use the drop-down menu in the Flow Object definitions and click the +.
As an example, a printer installation at a particular location connected to a particular router can be defined by a Flow Object that consists of:
- A printer Flow Object.
- ANDd a location Flow Object.
- ANDd a router Flow Object.
Or
- The Flow Object could define the IP address of a server and the web port(s).
A second Flow Object can be defined that will have its flow checked against the Allowed profile; this is an Entry profile.
Add Protocol/Port Application
To add a protocol or port application, click the Add protocol/port application icon and enter:
- Name: Name of the application.
- Protocol: the network protocol associated with the application.
- Port: the port number associated with the application.
Click Save.
Existing Defined Service
The Existing Defined Service table identifies the services based on the IP address, and/or Port, and/or Protocol. Once you add a defined service using the Add Defined Service button, it is included in the table.

The ID column shows the internal database ID used to identify the related service.
The Hits column shows the number of times this service has been seen in the flows.
The service Name is shown in your forensics applications reports.
In the Existing Defined Service table, you can perform the following actions:
To edit a defined service, click the Edit this object button in the related row, under the Actions column.
The EXISTING DEFINED SERVICE dialog shows.- To edit the fields, follow the steps used for the Add Defined Service procedure.

- To edit the fields, follow the steps used for the Add Defined Service procedure.
To delete a defined service, click the Delete button in the related row, under the Actions column.
The CONFIRMATION dialog shows.- Click the OK button.
To search for an item inside the table, enter the desired string in the Search field.
You can perform a search using keywords from all the columns present in the Existing Defined Service table.
Existing Defined Application
Already defined applications are listed here. Existing applications can be edited to associate icons.
Existing Flow Objects
Already defined flow objects are listed here.
Existing Protocol/Port Applications
Already defined protocol/port applications are listed here. Existing protocol/port applications can be edited to associate icons.
Attributes
Located at Configuration > Attributes.
Attributes are aliases used to help with identification of network infrastructure and users. Assigning an attribute category to a MAC address, user, IP, device or interface allows different user groups easily tag and identify your network infrastructure. For example, a network engineer may prefer to alias a device with a name or category appropriate to their view of your network. The security team may prefer a different categorisation.
The categories are:
- MAC Categories
- IP Categories
- User Categories
- Device Categories
- Interface Categories
The aim is to facilitate rapid identification of network infrastructure and user groups.
If you want to add a new device attribute:
- Click Configuration > Attributes
- Click +, Add.
- Enter the new attribute name and category type and then Save .
Cloud Services
AWS S3 Access
Configure GigaFlow to receive AWS VPC flow logs
The VPC Flow Log Ingestion function allows GigaFlow to treat AWS VPC flows in the same way as it handles the flow records. Hence, it provides the user the ability to report on on-premises and cloud based network traffic.
To enable the VPC Flow Log Ingestion function, perform the following steps:
- Create an S3 Bucket on the AWS portal https://docs.aws.amazon.com/AmazonS3/latest/userguide/creating-bucket.html.
- Enable the VPC flow logs on the VPC, the subnet, or the ENI interface of the EC2 instance that you intent to monitor
https://docs.aws.amazon.com/vpc/latest/userguide/flow-logs.html.
When you enable VPC flows, it is recommended to enable them for all VPCs rather than for individual interfaces, for 3 reasons:- This way it is easier to get broad visibility.
- Only instances provide interface IDs (ELBs and other infrastructure devices do not).
- This gives GigaFlow the best chance for deducing interface-pairs, vpc-pairs, and other such data from flow records which only include the interface and VPC they were emitted from.
Make sure that the following required fields at the minimum are included when you enable the VPC flow logs:
Field Operators type The type of traffic.
Possible values:- IPv4 or IPv6 addresses
- EFA (Elastic Fabric Adapter) interface - see https://aws.amazon.com/hpc/efa/.
accountid The AWS account ID of the owner of the source network interface for which the traffic is recorded. region The region that contains the network interface for which traffic is recorded. interface-id The ID of the network interface for which the traffic is recorded. instance-id If the instance is owned by you, then this represents the ID of the instance that is associated with the network interface for which the traffic is recorded.
It returns a '-' symbol for a requester-managed network interface (for example, the network interface for a NAT gateway).flow-direction The direction of the flow with respect to the interface where traffic is captured.
Possible values: ingress or egresssrcadd The source address for incoming traffic, or the IPv4 or IPv6 address of the network interface for outgoing traffic on the network interface. The IPv4 address of the network interface is always its private IPv4 address. dstadd The destination address for outgoing traffic, or the IPv4 or IPv6 address of the network interface for incoming traffic on the network interface. The IPv4 address of the network interface is always its private IPv4 address. pkt-srcaddr The packet-level (original) source IP address of the traffic. Use this field with the srcaddr field to distinguish between the IP address of an intermediate layer through which traffic flows, and the original source IP address of the traffic. For example: - When traffic flows through a network interface for a NAT gateway.
- When the IP address of a pod in Amazon EKS is different from the IP address of the network interface of the instance node on which the pod is running (for communication within a VPC).
pkt-dstaddr The packet-level (original) destination IP address for the traffic. Use this field with the dstaddr field to distinguish between the IP address of an intermediate layer through which traffic flows, and the final destination IP address of the traffic. For example: - When traffic flows through a network interface for a NAT gateway.
- When the IP address of a pod in Amazon EKS is different from the IP address of the network interface of the instance node on which the pod is running (for communication within a VPC).
srcport The source port of the traffic. dstport The destination port of the traffic. traffic-path The path that egress traffic takes to the destination. To determine whether the traffic is egress traffic, check the flow-direction field.
Possible values:- 1 - through another resource in the same VPC, including resources that create a network interface in the VPC
- 2 - through an internet gateway or a gateway VPC endpoint
- 3 - through a virtual private gateway
- 4 - through an intra-region VPC peering connection
- 5 - through an inter-region VPC peering connection
- 6 - through a local gateway
- 7 - through a gateway VPC endpoint (Nitro-based instances only)
- 8 - through an internet gateway (Nitro-based instances only).
- If none of the values apply, then the field is set to -.
flags The bitmask value for the following TCP flags: - FIN - 1
- SYN - 2
- RST - 4
- SYN-ACK - 18
- If no supported flags are recorded, then the TCP flag value is
0 .
TCP flags can be OR-ed during the aggregation interval. For short connections, the flags might be set on the same line in the flow log record (for example, 19 for SYN-ACK and FIN, and 3 for SYN and FIN).
See https://docs.aws.amazon.com/vpc/latest/userguide/flow-logs-records-examples.html#flow-log-example-tcp-flag for an example.protocol The IANA protocol number of the traffic. For more information, see Assigned Internet Protocol Numbers. packets The number of packets transferred during the flow. bytes The number of bytes transferred during the flow. action The action that is associated with the traffic: - ACCEPT - The traffic was accepted.
- REJECT - The traffic was rejected. For example, the traffic was not allowed by the security groups or network ACLs, or packets arrived after the connection was closed.
start The time, in Unix seconds, when the first packet of the flow was received within the aggregation interval. This might be up to 60 seconds after the packet was transmitted or received on the network interface. end The time, in Unix seconds, when the last packet of the flow was received within the aggregation interval. This might be up to 60 seconds after the packet was transmitted or received on the network interface. vpc-id The ID of the VPC that contains the network interface for which the traffic is recorded.
- Enable the access to services (S3/EC2). In order for GigaFlow to accesss the AWS services follow the procedure on this page AWS S3 VPC Flow Log Access.
- To configure GigaFlow with the AWS permissions using the API Key authentication method, in the GigaFlow UI go to Configuration > Cloud Services.
- Select the AWS tab, if not already selected, and perform the following steps:
Figure: AWS S3 API key Access

- In the Connection Name field, enter the name of the new connection that you want to create.
- In the Access Key field, enter the Acess key ID provided by AWS when you created it in your AWS account, on the Security Credentials page.
- In the Access Secret field, enter the Secret access key provided by AWS when you created the current access key.
Note:
Once the Access Key creation process ended, you will not have access to and cannot retrieve the Secret access key from the AWS platform. Make sure to store the Secret access key provided by AWS in a safe environment.
- The Virtual IP start field is used by GigaFlow when it cannot identify the IP address of an EC2 instance, but still it has information on the flows of the related interface(s).
In this field, enter the IP address for GigaFlow to use when it creates new virtual devices. The IP addresses of these virtual devices start with this given IP and are incremented by 1 with each new created device.
Default value:172.16.1.1 - If you do not want GigaFlow to add virtual devices related to the flows for which it has no EC2 details, then mark the Ignore Unknown Devices checkbox.
- In the Region Access Selection section, select the regions related to the S3 buckets from which you want to retrieve flow log data.
Note:
The polling of the S3 buckets takes place every 2 minutes for the selected buckets. Before the buckets are polled, GigaFlow collects EC2 information for all the selected regions. - To save the new connection, click the Add Or Update AWS Setting button.
- The S3 buckets related to the new connection are shown in the table under the Add Or Update AWS Setting button. For these buckets, you can take the following actions:
- To populate the GigaFlow database with information on the flows ingested from a bucket, mark the Bucket Ingestion State checkbox related to that bucket.
The state of the checkbox changes from off to the on position. - To delete all the log files related to a bucket, once ingested, mark the Delete flow log files after checkbox related to that bucket.
The state of the checkbox changes from off to the on position.
Note:
If you do not want to use this Delete feature and you want to store the log files for later use on AWS, then VIAVI provides a script to migrate the log files.To store the VPC log files for a longer duration while at the same time not progressively increasing the time for GigaFlow polling AWS for available logs, we suggest moving these logs from the S3 bucket into an AWS Lambda service instance.
At the following link you can find an example of this migration procedure: Create script for AWS Lambda to migrate old VPC flow logs.
- To populate the GigaFlow database with information on the flows ingested from a bucket, mark the Bucket Ingestion State checkbox related to that bucket.
In case you experience delays in AWS when transferring VPC flow logs to the S3 bucket, they can set the Flow Reception Window to a corresponding covering value and the Client Buffer Window to that value plus 2 minutes, to have GigaFlow and Apex synchronized for this situation. For example, if you experience AWS VPC flow logs delivery delays fluctuating under 15 minutes, then set the GigaFlow Flow Reception Window to 15 minutes (900000 milliseconds) and the Client Buffer Window to 17 minutes (1020000 milliseconds). |
Modify an existing connection
To edit a previously created connection, perform the following steps:
- In the Actions column related to the row of the connection you want to modify, click the Edit AWS Connection button.
- Edit the fields or checkboxes that need modifications.
- To save your changes, click the Add Or Update AWS Setting button.
Delete a connection
To delete an existing connection, perform the following steps:
- In the Actions column related to the row of the connection you want to delete, click the Remove AWS API button.
- In the popup dialog, click the OK button.

Click the
- Query the AWS S3 buckets.
- Download the AWS S3 buckets.
- Parse flows into the Gigaflow database.
The AWS Bucket Statistics page opens in a new tab. On this page you can also see how many records GigafLow found per S3 file.

The Private Networks functionality is used to determine what cloud based traffic is internal to your organisation and what traffic is external.
The external traffic is then marked as

In the Private Networks frame, Gigaflow first adds the following private networks:
10.0.0.0/8 169.254.0.0/16 172.16.0.0/12 192.168.0.0/16
Then GigaFlow scans your associated AWS account for all subnet information. Using this information GigaFlow creates the so called supernets which are used to define what IP addresses are private to the customer, everything else is considered public traffic.
In the New Private Network frame, Gigaflow lets you add your own private networks. To do this, perform the following steps:
- In the Name field, enter the name of the server that you want to add.
Possible values: alphanumeric ASCII characters string
Default setting: empty field - In the Network IP Address field, enter the IP of the subnet that you want to add.
Possible values: IPv4 addresses
Default setting: empty field - In the Network Mask field, enter the subnet mask of the server that you want to add.
Possible values: IPv4 addresses
Default setting: empty field - Click the Save button.
GigaFlow adds your new private network to the Private Networks table.
The AWS EC2 Discovered Subnet Information frame lets you see the AWS discovered subnets. When you add your AWS credentials, GigaFlow uses them to gather the subnet information and populate this table.
To refresh this AWS subnet table, click the Refresh button in the upper-left corner of the AWS EC2 Discovered Subnet Information frame. The refresh request can take up to 2 minutes to complete.
Subnets are automatically obtained from AWS every 1 hour. |
Only the largest subnets are kept to identify the public or private traffic. For example, since subnet
To see a list of all EC2 information collected by GigaFlow for use during enrichment of device and interface information in the GigaFlow UI, click the
The AWS EC2 Instance Information page opens in a new tab.

Specific device reports
To see the reports on a specific device, perform the following steps:
- In the GigaFlow UI, click on the Dashboards left menu.
- In the Top Devices widget click on the desired device.
The Enterprise Dashboard for the selected device opens.
- In the Summary Device Interfaces Flow widget, click on the blue drill-down arrow related to the desired
eni- interface.The Forensics dashboard for the selected interface opens.
- In the Report drop-down, list select the All Fields option.
- In the Output drop-down, list select the Table option.
- Click the gray Apply filters check mark.
As a result, GigaFlow shows a list with every individual flow record related to that specific interface.
AWS IAM role based authentication
GigaFlow supports IAM (Identity and Access Management) role based access control to retrieve VPC logs from S3 Buckets. The role must have permission to access S3 buckets and EC2 instances.
AWS System Manager installation
For your initial authentication and connection to AWS, GigaFlow needs access to a credentials file. The AWS System Manager must be installed on the GigaFlow server following the Hybrid Activation process. The following link describes the installation process: Install SSM Agent on hybrid Windows Server nodes.
The next 2 sections describe some additional configurations for this setup to work for on-premises Windows and Linux GigaFlow servers.
Windows
The AWS System Manager typically writes the credentials file to the
This is only for the on-premises GigaFlow server.
Linux
On Linux the AWS System Manager is installed as root and writes the credentials file to
After the successful registration of the AWS System Manager, perform the following steps:
- Open a terminal prompt with suitable permissions.
- Run the following command:
systemctl stop gigaflow - Edit the
/usr/lib/systemd/system/gigaflow.service file to add the following line in the Service section:Environment="AWS_SHARED_CREDENTIALS_FILE=/opt/ros/.aws/credentials" - To reload the configuration, run the following command:
systemctl daemon-reload - Start the cron-job using the cron_setup.sh script in the
/opt/ros/resources/unix folder. - Make sure that the credentials file exists in the
/opt/ros/.aws/ location. - To start GigaFlow, run the following command:
systemctl start gigaflow
Configure an AWS connection using IAM Role authentication
- In the GigaFlow UI go to Configuration > Cloud Services.
- If not already selected, then select the AWS tab.
Figure: AWS IAM role based access control

- In the Connection Name field, enter the name of the new connection that you want to create.
- Mark the Use IAM Role to Retrieve Buckets checkbox.
The Access Key and Access Secret fields are hidden.
The Role ARN field shows. This field is required for the connection validation.Note:
To use the IAM Role authentication method, it requires an AWS IAM role with S3 read permissions attached to the EC2 instance(s) or hybrid activation configured. To see EC2 devices, EC2 list permissions are also required. - In the Role ARN field, enter a valid AWS Role ARN (Amazon Resource Name) in the following format:
arn:aws:iam::[account-id]:role/[role-name]
Maximum number of characters: 2048Example:
arn:aws:iam::123456789012:role/MyRole - The Virtual IP start field is used by GigaFlow when it cannot identify the IP address of an EC2 instance, but still it has information on the flows of the related interface(s).
In this field, enter the IP address for GigaFlow to use when it creates new virtual devices. The IP addresses of these virtual devices start with this given IP and are incremented by 1 with each new created device.
Default value:172.16.1.1 - If you do not want GigaFlow to add virtual devices related to the flows for which it has no EC2 details, then mark the Ignore Unknown Devices checkbox.
- In the Region Access Selection section, select the regions related to the S3 buckets from which you want to retrieve flow log data.
Note:
The polling of the S3 buckets takes place every 2 minutes for the selected buckets. Before the buckets are polled, GigaFlow collects EC2 information for all the selected regions. - To save the new connection, click the Add Or Update AWS Setting button.
- The S3 buckets related to the new connection are shown in the table under the Add Or Update AWS Setting button. For these buckets, you can take the following actions:
- To populate the GigaFlow database with information on the flows ingested from a bucket, mark the Bucket Ingestion State checkbox related to that bucket.
The state of the checkbox changes from off to the on position. - To delete all the log files related to a bucket, once ingested, mark the Delete flow log files after checkbox related to that bucket.
The state of the checkbox changes from off to the on position.
Note:
If you do not want to use this Delete feature and you want to store the log files for later use on AWS, then VIAVI provides a script to migrate the log files.To store the VPC log files for a longer duration while at the same time not progressively increasing the time for GigaFlow polling AWS for available logs, we suggest moving these logs from the S3 bucket into an AWS Lambda service instance.
At the following link you can find an example of this migration procedure: Create script for AWS Lambda to migrate old VPC flow logs.
- To populate the GigaFlow database with information on the flows ingested from a bucket, mark the Bucket Ingestion State checkbox related to that bucket.
To configure GigaFlow with the AWS permissions using the IAM Role authentication method, perform the following steps:
In case you experience delays in AWS when transferring VPC flow logs to the S3 bucket, they can set the Flow Reception Window to a corresponding covering value and the Client Buffer Window to that value plus 2 minutes, to have GigaFlow and Apex synchronized for this situation. For example, if you experience AWS VPC flow logs delivery delays fluctuating under 15 minutes, then set the GigaFlow Flow Reception Window to 15 minutes (900000 milliseconds) and the Client Buffer Window to 17 minutes (1020000 milliseconds). |
Azure Access
The NSG and VNET Flow Log Ingestion function allows GigaFlow to treat Azure NSG and VNET flow logs in the same way as it handles the flow records. Hence, it provides the user the ability to report on on-premises and cloud based network traffic.
Get your Azure Subscription ID
To obtain your Subscription ID in Azure, perform the following steps:
- Login to the Azure Portal.
- In the Search bar from the top of the main page, enter the folowing string: subscriptions.
A results dialog shows.
- In the results dialog, click the Subscriptions option from the Services frame.
- From the Subscription ID column, copy the ID related to the subscription you want to use.
Note:
Save the Subscription ID to a text file. You will use this code later in the configuration process, in the GigaFlow UI.
Add a registered application in Azure
To add a registered application in Azure, perform the following steps:
- Login to the Azure Portal.
- In the Search bar from the top of the main page, enter the folowing string: microsoft entra id.
A results dialog shows.
- In the results dialog, click the Microsoft Entra ID option from the Services frame.
- In the left panel, click the App registrations button.
The App registrations page shows.
- In the top of the page, click the + New registration button.
The Register an application page shows.
- In the Name field, enter the name of the application that you want to register.
- In the Supported account types list, select the Accounts in this organizational directory only (Single tenant) radio button.
- In the bottom of the page, click the Register button.
You are redirected to the registry page of the new application.
- Copy the Application (client) ID and the Directory (tenant) ID strings for later use.
- In the left panel, click the Certificates & secrets button.
The Certificates & secrets page shows.
- To add a client secret, click the + New client secret button.
The Add a client secret popup dialog shows on the right side.
- In the Description field, enter an identifier for the secret you want to create.
- In the Expires drop-down list, select the expiration duration of the secret.
- In the bottom of the dialog, click the Add button.
The newly created secret shows in the Client secrets tab.
- From the Value column, copy the string related to the secret you just created for later use.
For more details on adding a registered application in Azure, access the following link Quickstart: Register an application with the Microsoft identity platform. |
Assign permissions to the storage and the Virtual Machine (VM)
To assign permissions to the storage and the VM, perform the following steps:
Add the Storage Blob Data Reader role
- Login to the Azure Portal.
- In the Search bar from the top of the main page, enter the folowing string: storage accounts.
A results dialog shows.
- In the results dialog, click the Storage accounts option from the Services frame.
- In the Storage accounts page, click the account you want store your flow logs.
The overview page related to that storage account shows.
- In the left panel, click the Access Control (IAM) button.
- In the Access Control (IAM) dialog, click the + Add drop-down list and select the Add role assignment option.
The Add role assignment page shows.
- In the Role tab Search bar, enter the folowing string: storage blob data reader.
- In the Job function roles list, select the Storage Blob Data Reader role and click the Next button.
- In the Members tab, click the + Select members button.
The Select members popup dialog shows on the right side.
- In the Select search bar, enter the name of the application you previously registered.
- Select the apllication and click the Select button.
- In the Add role assignment page, click the Review + assign button two times.
The expected result is for the Added Role assignment message to show in the top right of the dialog.
Add the Reader and Data Access role
- In the Access Control (IAM) dialog, click the + Add drop-down list and select the Add role assignment option.
The Add role assignment page shows.
- In the Role tab Search bar, enter the folowing string: reader and data access.
- In the Job function roles list, select the Reader and Data Access role and click the Next button.
- In the Members tab, click the + Select members button.
The Select members popup dialog shows on the right side.
- In the Select search bar, enter the name of the application you previously registered.
- Select the apllication and click the Select button.
- In the Add role assignment page, click the Review + assign button two times.
The expected result is for the Added Role assignment message to show in the top right of the dialog.
Add the Virtual Machine Contributor role
- In the Search bar from the top of the main page, enter the folowing string: subscriptions.
A results dialog shows.
- In the results dialog, click the Subscriptions option from the Services frame.
- In the Subscriptions page, click the subscription that you want use.
The overview page related to that subscription shows.
- In the left panel, click the Access Control (IAM) button.
- In the Access Control (IAM) dialog, click the + Add drop-down list and select the Add role assignment option.
The Add role assignment page shows.
- In the Role tab Search bar, enter the folowing string: virtual machine contributor.
- In the Job function roles list, select the Virtual Machine Contributor role and click the Next button.
- In the Members tab, click the + Select members button.
The Select members popup dialog shows on the right side.
- In the Select search bar, enter the name of the application you previously registered.
- Select the apllication and click the Select button.
- In the Add role assignment page, click the Review + assign button two times.
The expected result is for the Added Role assignment message to show in the top right of the dialog.
Add the Reader role
- In the Access Control (IAM) dialog, click the + Add drop-down list and select the Add role assignment option.
The Add role assignment page shows.
- In the Role tab Search bar, enter the folowing string: reader.
- In the Job function roles list, select the Reader role and click the Next button.
- In the Members tab, click the + Select members button.
The Select members popup dialog shows on the right side.
- In the Select search bar, enter the name of the application you previously registered.
- Select the apllication and click the Select button.
- In the Add role assignment page, click the Review + assign button two times.
The expected result is for the Added Role assignment message to show in the top right of the dialog.
If you do not have your NSG Flow logs enabled in Azure, follow the Enable the microsoft.insights provider and the Enable the NSG Flow logs procedures.
Enable the microsoft.insights provider
To enable the microsoft.insights resource within your subscription, perform the following steps:
- Login to the Azure Portal.
- In the Search bar from the top of the main page, enter the folowing string: subscription.
A results dialog shows.
- In the results dialog, click the Subscritions option from the Services frame.
- In the Subscriptions page, click the subscription that you want use.
The overview page related to that subscription shows.
- In the left panel, click the Resource providers button.
The Resource providers dialog shows.
- In the Filter by name... search bar, enter the string: microsoft.insights.
- In the list, click on the microsoft.insights provider.
- In the top of the dialog, click the Register button.
Note:
Wait until the provider is registered.
To enable the NSG Flow logs, perform the following steps:
- In the Search bar from the top of the main page, enter the following string: network watcher.
A results dialog shows. - In the results dialog, click the Network Watcher option from the Services frame.
- In the left panel of the Network Watcher page, click the Flow logs button.
The Flow logs dialog shows. - In the top of the page, click the + Create button.
- In the Create a flow log page, click the + Select resource button.
The Select network security group page shows. - Mark the checkbox(es) related to the NSG(s) for which you want to enable the flow logs.
- Click the Confirm selection button.
You are redirected back to the Create a flow log page. - In the Retention (days) field, enter the number of days for whitch you want data to be stored.
- Click the Review + create button and wait until the Deployment succeeded message shows in the top right of the page.
- In the bottom of the page click the Create button.
After you enabled the NSG Flow logs in Azure, wait until the storage container has data, then go to GigaFlow and rescan the account to detect the new storage container. |
For more details on enabling the NSG Flow logs in Azure, access the following link: Flow logging for network security groups. |
If you experience delays in Azure when transferring flow logs to the container, then you can set the Flow Reception Window to a corresponding covering value and the Client Buffer Window to that value plus 2 minutes, to have GigaFlow and Apex synchronized for this situation. For example, if you experience Azure flow logs delivery delays fluctuating under 15 minutes, then set the GigaFlow Flow Reception Window to 15 minutes (900000 milliseconds) and the Client Buffer Window to 17 minutes (1020000 milliseconds). |
If you do not have your VNET Flow logs enabled in Azure, follow the Enable the microsoft.insights provider and the Enable the VNET Flow logs procedures.
For the latest instructions on enabling the VNET Flow logs in Azure, access the following link: Create a flow log. |
To enable the VNET Flow logs, perform the following steps:
- In the Search bar from the top of the main page, enter the following string: network watcher.
A results dialog shows. - In the results dialog, click the Network Watcher option from the Services frame.
- In the left panel of the Network Watcher page, click the Flow logs button.
The Flow logs dialog shows. - In the top of the page, click the + Create button.
- On the Basics tab of the Create a flow log page, enter or select the following values:
Setting Value Project details Subscription Select the Azure subscription of your virtual network that you want to log. Flow log type Select the Virtual network radio-button and then click the + Select target resource drop-down list. The available options are the following: - Virtual network
- Subnet
- Network interface
Flow Log Name Enter a name for the flow log or leave the default name.
Azure portal uses {ResourceName}-{ResourceGroupName}-flowlog as a default name format for the flow log.Instance details Subscription Select the Azure subscription of the storage account. Storage accounts Select the storage account that you want to save the flow logs to.
If you want to create a new storage account, then click the Create a new storage account blue button.Retention (days) Enter a retention period for the logs.
If you want to retain the flow logs data in the storage account forever (until you manually delete it from the storage account), then enter the value 0.
- Click the Review + create button and wait until the Deployment succeeded message shows in the top right of the page.
- In the bottom of the page click the Create button.

After you enabled the VNET Flow logs in Azure, wait until the storage container has data, then go to GigaFlow and rescan the account to detect the new storage container. |
For more details on enabling the VNET Flow logs in Azure, access the following link: Virtual network flow logs. |
Configure access to Azure in GigaFlow UI
To configure your access to Azure in the GigaFlow UI, perform the following steps:
- In the GigaFlow UI, go to the Configuration > Cloud Services > Azure tab.
- In the Connection Name field, enter the name of the new connection that you want to create.
- In the Subscription ID field, enter the ID that you saved in the Get your Azure Subscription ID section at step 4.
- In the Tenant ID field, enter the Directory (tenant) ID that you saved in the Add a registered application in Azure section at step 9.
- In the Client ID field, enter the Application (client) ID that you saved in the Add a registered application in Azure section at step 9.
- In the Client Secret field, enter the Value string that you saved in the Add a registered application in Azure section at step 15.
- To save the new connection, click the Add Or Update Azure Setting button.
Note:
A popup message notifies you that a test is performed to check the correctness of the information you provided. If there are a large number of resources to collect, then the process may take some time to complete.

Modify a connection
To edit a previously created connection, perform the following steps:
- In the Actions column related to the row of the connection you want to modify, click the Edit Azure Connection button.
- Edit the fields that need modifications.
- To save your changes, click the Add Or Update Azure Setting button.
Delete a connection
To delete an existing connection, perform the following steps:
- In the Actions column related to the row of the connection you want to delete, click the Remove Azure API button.
- In the popup dialog, click the OK button.
To refresh an existing connection, perform the following steps:
- In the Actions column related to the row of the connection you want to refresh, click the Refresh Azure API button.
GigaFlow immediately sends a new request to Azure for storage account, VM instance, and flow log records.
Azure NSG flows information links

VM Instances
Click the
The Azure VM Instance Information page opens in a new tab. For each VM discovered by GigaFlow, this page displays all the attributes available from Azure, including the following:
- Instance ID
- Region
- Computer name
- OS type.

Storage Accounts
Click the
The Azure Storage Account Information page opens in a new tab. This page displays the following:
- Which accounts are collecting stats.
- For how many MAC addresses (devices) are stats collected.
- How much data the most recent collection ingested.
- How long the most recent collection took.

To display which MAC addresses are being monitored and the IP address of the related device, perform the following steps:
- Click on a storage account in the Name column.
The Azure Storage Account Container frame shows.
- To start collecting data on that storage account, switch on the Collection Enabled toggle button.
Note:
To force the process, refresh the connection in the Cloud Services > Azure tab. - Use the Ignore Unknown toggle button in the following ways:
- If this button is switched off, then all traffic is ingested from all the VMs, not only the ones that are being discovered.
- If this button is switched on, then the only proccessed traffic is for the discovered devices.
- For detailed device information, click the related Device IP Address.
- To display the most recent 100 blocks that have been downloaded for a MAC address from Azure, click the related MAC.
The Azure Storage MAC Address Blocks frame shows.
Note:
This table displays how long it took to process each block of NSG log data, its size, and what period it covered.
GEOIP
Located at Configuration > GEOIP.
You can change the geolocation and IP settings here.
To add new GEOIP overrides:
- Enter comma-separated parameters as follows:
"Start IP,End IP,Country ISO Code,Region Name,Latitude,Longitude"
- or
"IP/MaskBits,Country ISO Code,Region Name,Latitude,Longitude.
- Click Add GEO to IPs.
A table of existing GEOIP overrides is shown in the table below this.
You can select the number of items to show from the dropdown menu above the table; the default is 50 items.
Information displayed includes:
- Start IP.
- End IP.
- Country ISO code.
- Region name.
- Latitude.
- Longitude.
- List of actions you can perform, i.e. modify or delete entries.
You can also search by entering a country code or clicking on the map below the table.
Infrastructure Devices
Located at Configuration > Infrastructure Devices.
Actions
Add Device
To add a new infrastructure device:
- Enter the IP address.
- Enter the SNMP community.
- Click Save to save changes.
Add Bulk Devices
To bulk-add new devices, i.e. more than one device at a time:
- Enter device information using the format:
ip
- or
ip, communityString
- or
ip, communityString, deviceName
Use a new line for each new device added.
Recheck Forensics
Recheck Forensics by clicking Refresh ![]() .
.
Extended Stats
This shows a more detailed version of the Existing Devices table, with additional statistics for each device.
Existing Devices
The Existing Device(s) table lists all connected infrastructure devices.
You can select how many of the devices to view, i.e. the most recent 10, 25, 50, 100 or all devices.
At the top of the table, the total number of infrastructure devices is given. You can also search for a particular device. Each column is sortable. The table displays interactive information, including:
- Device ID. To view a detailed overview of this device, click on the IP. See the next section, Detailed Device Information. The Device ID is assigned when the system receives a flow or syslog from it for the first time.
- Device IP address. It is good practice to ensure that the source address is fixed, ideally, to a VLAN or management VLAN address. Otherwise, multiple entries might be created for each alternative pathway.
- SNMP IP: IP address for SNMP access.
- Device name. To change the device name, enter a new name and click Save . This defaults to the IP address or the SNMP system name if this exists. Both can be overwritten.
- SNMP state, up or down. This indicates whether or not the sender can be polled for more information. To refresh the SNMP state, click Refresh
 .
. - SNMP Success Rate - shows the percentage of the SNMP requests that have succeeded for the related device.
- Number of associated Layer-3 interfaces.
- Number of VLANs.
- Number of ARPs.
- Number of BPNs.
- Number of CAM (latest).
- Number of CAMs.
- Number of LLDPs.
- Latest SNMP Duration - the duration of the last SNMP response in milliseconds.
- Number of Drops.
- Flows per second. This is GigaFlow's current flow processing rate.
- Number of Flows. This is the total number of flows received by GigaFlow since the last reset or restart, not including duplicates.
- Sampling rate.
- Trigger. This is the flow resolution used in the flows per second calculation.
- Associated Netflow templates.
- Number of forensics.
- Stored MB. This is the storage used for the sender's flow/syslog information.
- GBs. This is the storage limit for the sender's flow/syslog information. When this limit is exceeded, the system will purge the oldest entries.
- Oldest entry.
- Store (yes or no.) See also System > Global > Storage. If the sender's flows/syslogs are stored or not. If not, they will be checked, still, against blacklists and Profilers.
- Associated System Object Identifier (SysOID).
- Number of duplicate flows discarded (if any).
Device SNMP Mapping
The Device SNMP Mapping table displays:
- System Object Identifier (SysOID).
- Poller. To change the poller, select from the drop-down list and click Save .
- The number of devices using this SysOID.
- A description of the system, e.g. Gigabit Smart Switch.
Detailed Device Information
Located at Configuration > Infrastructure Devices > Detailed Device Information.
By clicking any device IP address in the Existing Devices table, you can bring up a detailed overview of that device.
On loading, the device name, device IP address and device ID are given across the top of the page.
SNMP Settings
Below this information, you will see the SNMP Settings panel. SNMP information is listed here. This includes:
- Date and time of last SNMP details poll.
- Date and time of last SNMP Interfaces poll.
- Last SNMP duration in milliseconds.
- Date and time of last DSP check.
- SNMP Location.
- Number of interfaces.
- Device description.
- Device ObjectID.
- Device poller.
- Device name.
- Templates, e.g. V5.
- Flows: more detail can be shown by clicking the drill down arrow.
To change the device name:
- Enter the new name in the text box.
- Click Save to save changes.
Note:
For the flows ingested from cloud providers (for example, AWS or Azure), GigaFlow will use the Infrastructure Device name that the cloud provided. If you change the Infrastructure Device name to a custom one, then all the newly ingested flows from the cloud, for that reporting device IP, will actually overwrite its name.
To change SNMP version and/or community:
- Select a version number from the drop-down box.
- Enter a community name.
- Click Save to save changes.
- Click Test SNMP Fields to test these settings.
To test SNMP settings and status:
- Click Refresh to refresh status.
- You will see a green Up arrow indicating that SNMP is up or a red Down arrow if SNMP is down.
All other device information is populated automatically from the device and cannot be edited.
SNMP Information Gathered
The following describes what data is collected by each SNMP collection type:
- No Collections - disables collections of all SNMP data.
- Basic SNMP Information - gathers only host and interface information (including interface IPs).
- No Interface Stats - disables Interface Statistics but still gathers everything else.
- Default Infrastructure Device - gathers all the information found in the below Default Infrastructure Device (Above plus) section.
In the following table you can find what data is collected depending on the collection type:
| Collection Name | Collection Entry | Poll Interval | Description |
|---|---|---|---|
| Basic SNMP Information | |||
| SNMP System Details | 30 minutes | Collects sysDescr, sysName, sysObjectID, sysUpTime, sysLocation via SNMP. | |
| SNMP Interface Details | 30 minutes | Collects Interface Information such as speed and duplex via SNMP. | |
| SNMP Interface IPs | 30 minutes | Collects IP Address Information from Interfaces. | |
| Default Infrastructure Device | |||
| SNMP System Details | 30 minutes | System information | |
| SNMP Interface Details | 30 minutes | Interface details | |
| SNMP LLDP Tables | 30 minutes | Neighbouring devices using LLDP or CDP. | |
| SNMP Interface IPs | 30 minutes | Interface IP addresses | |
| SNMP ARP Tables | 1 hour | ARP tables mapping IP to MAC addresses. | |
| SNMP IP Net To Media | 30 minutes | Interface mapping IP to MAC addresses. | |
| SNMP VLAN Tables | 30 minutes | VLAN Tables | |
| SNMP CAM Tables | 1 hour | CAM tables mapping MAC address to interfaces. | |
| SNMP Interface Octets | snmpinterfaceperiod* | Interface octet count | |
| SNMP Interface Packets | snmpinterfaceperiod* | Interface packet count | |
| SNMP Interface Errors | snmpinterfaceperiod* | Interface error count | |
| SNMP Interface State | snmpinterfaceperiod* | Interface State | |
| Router Infrastructure Device | |||
| Same as Default | Same as Default | All collections except SNMP CAM Tables | |
| No Interface Stats | |||
| System + Discovery only | Various | System details, interfaces, LLDP, IPs, ARP, VLAN, CAM (no statistics) |
Device SNMP Issues
This section identifies the issues that show on a particular device. It shows the queried OID(s) (Object Identifiers) of a device for which GigaFlow had issues and the number of times it tried the query resulting in that issue.

The Empty response table shows when the SNMP query was successful, but the table returned was empty.
The No response shows when there was no response to the SNMP query. This can occur due to bad credentials or due to the security configuration on the end device.
Attributes and Tools
To add attributes to the device:
- Select a device type from the drop-down menu.
- Enter a name for the attribute and click + to add.
- To remove an attribute, click the small x.
There are quick-links to useful tools, including:
- Forensics.
- ARPs.
- CAMs.
- Int Tools.
- Traffic Overview.
And links to associated integrations (Integrations) and servers (Server Discovery). See also System > Global for more about integrations.
See Reports > Forensics for more.
Storage Setting
In this panel, you can view and make changes to the device information storage settings:
- Storage profile name.
- Allowed disk duration, set to 14 days.
- Allowed disk storage (GB). This defaults to 1 GB. To change this, enter a new value and click Save .
- Process flows. You can change this by selecting from the drop-down menu. The choices are:
- Yes.
- No forensics storage.
- No processing.
- Store seen IP, Yes or No.
- Sample rate, per second.
- Time and date of oldest Disk Storage.
- Click Save after making a change.
- Sample rate. This defaults to 1 millisecond. To change this, enter a new value and click Save .
- To remove a device, click Remove Device.
At the bottom of the detailed infrastructure device settings page, there are several tabs:
- Interfaces.
- Subnets.
- Flow Templates.
- Stats.
- VLANs.
- Bridge Ports.
- Bridge Ports To IF Index.
- Application mapping.
Other Settings
The Interfaces tab consists of an editable table with the following information:
- IfIndex: the interface number.
- The interface name. To change this, enter a new name and click Save .
- The interface alias. To change this, enter a new alias and click Save .
- The interface description. To change this, enter a new value and click Save .
- The interface IP address.
- The interface MAC address.
- Speed In (MB/s). To change this, enter a new value and click Save .
- Speed Out (MB/s). To change this, enter a new value and click Save .
- Admin status.
- Oper status.
The Subnets tab displays a list of SNMP discovered subnets. See also Reports > System Wide Reports > Subnet List.
The Flow Templates tab displays a list of the Netflow templates used, e.g.:
- V9 Templates.
- V10 Templates.
- NSEL Templates.
The Stats tab consists of a list of the number of VLAN, ARP and CAM entries.
The VLANs tab consists of a list of VLANs.
The Bridge Ports tab consists of a list of bridge ports.
The Bridge PortNumbers To ifIndex tab consists of a list of bridge ports.
The Application Mapping tab displays a list of mapped applications with the key, appid and application listed for each mapping.
The SNMP Stats tab consists of a table that contains all the statistics for the SNMP requests sent by the device. This is the same table as on the System Status > SNMP Stats page, except for the 2 columns used to identify the device: Device IP and Device Name.
Profiling
Host Profiler Wizard
Enter:
- Name and description. Click Next.
- Client addresses, i.e. devices whose traffic will be monitored. These devices can be identified by IP or MAC Address. You can enter single IP Addresses, range or subnet e.g. 1.1.1.0/255.255.255.0. Or you can enter MAC Address or range e.g. 00:0c:29:82:c8:85,00:0c:29:00:00:00-00:0c:29:ff:ff:ff. Click Next.
- Allowed applications. Select an application from the drop-down list or create a new application at Configuration > Applications.
- Click Submit.
Service Profiler Wizard
Enter:
- Name and description. Click Next.
- Allowed traffic patterns, i.e. allowed applications/services. Select an application from the drop-down list or create a new application at Configuration > Applications. Click Next.
- Client addresses, i.e. devices whose traffic will be monitored. These devices can be identified by IP or MAC Address. You can enter single IP Addresses, range or subnet e.g. 1.1.1.0/255.255.255.0. Or you can enter MAC Address or range e.g. 00:0c:29:82:c8:85,00:0c:29:00:00:00-00:0c:29:ff:ff:ff. Click Next.
- Allowed server addresses, i.e. servers whose use is allowed. These devices can be identified by IP or MAC Address. You can enter single IP Addresses, range or subnet e.g. 1.1.1.0/255.255.255.0. Or you can enter MAC Address or range e.g. 00:0c:29:82:c8:85,00:0c:29:00:00:00-00:0c:29:ff:ff:ff.
- Click Submit.
Add Profiler
Located at Configuration > Profiling.
This is where you can create profiles that define the normal behaviour of your network.
- Profiling is a very powerful feature.
- A Flow Object is a logical set of defined flows and IP source and destination addresses.
- Flow objects make it possible to build up a complex profile or Profiler quickly. These terms are used interchangeably.
- A particular network behaviour that involves network flow objects is described by a Profiler.
To get going, create your first profile.
- A good way to start is to select one type of device and a single IP of this type.
- For example, in retail, this might be a point of sale machine.
- Then build a profile based on expected flows out of the device IP.
- This profile can serve as a template for realtime monitoring; this is an Allowed profile.
Step one is then to create a new Flow Object at Configuration > Applications. To create a flow object:
To create a new Profiler (this term is used interchangeably with profile):
- Go to Configuration > Profiling.
- Give the new Profiler a name and description.
- Select an Entry profile (the profile to be monitored) and an Allowed profile (the acceptable profile) from the drop-down lists. The Entry and Allowed profile selection includes basic flow objects, i.e. individual devices on your network. A profile is a flow object that is itself a combination of flow objects.
- If you want to be alerted when an exception occurs, select Yes from the drop-down menu.
- Click Save.
Existing Profilers
This table displays a list of existing profiles.
- ID: the profile ID.
- Name: the name of the profile.
- Description: a description of the profile.
- Entry: the Entry profile is the profile that is to be monitored.
- The Entry and Allowed profile selection includes basic flow objects, i.e. individual devices on your network. A profile is a flow object that is itself a combination of flow objects.
- Allowed: the Allowed profile is the target, or acceptable, profile.
- The Entry and Allowed profile selection includes basic flow objects, i.e. individual devices on your network. A profile is a flow object that is itself a combination of flow objects.
- Checks: this is the number of times that the profiles were compared.
- Hits: this is the number of matches between the Entry and Allowed profiles.
- Exceptions: the number of times that the flow records for this profile that have deviated from the ideal, or Allowed, profile.
- Alert: this is set to true or false - if an alert is raised when an exception is detected, this is set to true.
- Actions: profiles can be edited, the exception count can be reset and the profile rank order can be raised or lowered.
Reporting
Located at Configuration > Reporting.
One of the difficult aspects of reporting on network flows is the number of possible field combinations, with 25+ fields in the extended range. GigaFlow records all fields for all flows with no summarization and no deduplication. GigaFlow allows you to create exactly the report you want.
You can change reporting settings here, in the General and Forensics Reports panels.
Add Report Link
Allows you to add new entries to be displayed in the left hand navigation under the Reports option.
You can enter:
- The URL to be called (must be unique).
- The name displayed in the left had menu for this URL.
- Whether this url should be opened in a new window (YES) or the GigaFlow main content frame (NO)
Import Report Link
Allows you to import a JSON representation of new entries to be displayed in the left hand navigation under the Reports option.
General
You can edit the general reporting settings in this panel:
- Default search period: select 1 day, 2 days, 7 days, 14 days or 21 days. The default selection is 1 day.
- Forensics graph summary rows: select 5, 10, 20, 30, 40 or 50 rows. The default selection is 10 rows.
- Default reporting period: the default reporting period is 10 minutes, i.e. the last 10 minutes of information will be presented.
- Maximum number of table rows to return: select 1,000, 5,000, 10,000, 20,000, 50,000, 100,000 or 1,000,000. The default selection is 1,000,000.
- Default Forensics Report: Select which report should automatically run when going from a summary report to a forensics report.
- The default selection is Application Flows.
- Show Cumulative Stacked Chart Values.
- Show Stacked Charts.
- Chart Format.
- Chart Format Custom Settings.
- Click Save Report Settings to save changes or Cancel to clear changes not submitted.
Forensics Reports
See Appendix > Forensic Report Types for a complete description of the different report types. See also Reports > Forensics for the Direct Filtering Syntax used by GigaFlow.
You can view and clone built-in forensics reports in this panel.
From the Report drop-down menu, select the report type to view or clone. The default selection is Application Flows. In the panel below, you can view:
- The report name.
- The associated table query, in this case:
select srcadd as srcadd,dstadd as dstadd,appid as appid, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcadd,dstadd,appid ORDERBY LIMITROW
- The table value field, in this case:
bits_total
- The graph query, in this case:
select FIRSTSEEN as afirstseen,srcadd as srcadd,dstadd as dstadd,appid as appid, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcadd,dstadd,appid order by srcadd,dstadd,appid,afirstseen
- The graph time field, in this case:
afirstseen
- The graph value field, in this case:
bits_avgsec
- The graph key field(s), separated by "__", in this case:
srcadd__dstadd__appid
To clone a report:
- Enter the new cloned report name.
- Click Clone Forensics Report to create new cloned report.
Existing DSCP Names
- This is a list of existing, editable DSCP names.
- Click Save DSCP Names to commit any changes.
New DSCP Name
To add a new DSCP name:
- Enter the DSCP number.
- Enter the new name.
- Click Save DSCP Name.
Existing Report Links
Lists the existing user defined report URLS that are available from the left hand navigation under the Reports option.
The table lists:
- The URL to be called (must be unique).
- The name displayed in the left had menu for this URL.
- Whether this url should be opened in a new window (YES) or the GigaFlow main content page (NO).
Server Subnets
Located at Configuration > Server Subnets. See also Reports > First Packet Response.
To begin using First Packet Response (FPR), you must specify the server subnets and ports that you would like to monitor. FPR monitors TCP and UDP traffic, e.g. DNS 53/UDP, and is inherently multi-threaded by device.
Add Server Subnet
To add a new server subnet:
- Click + at the top of the page.
- Enter the subnet address.
- Enter the subnet mask.
- Click Add Server Subnet.
- Click Cancel to clear the data entered.
Server Subnets
This tab allows you to view a list of existing monitored server subnets and to add new subnets. The main table displays the following information:
- ID.
- Subnet.
- Mask.
- Ports.
Actions, i.e. edit or delete a subnet. Editing a subnet allows you to specify a particular port to monitor.
Servers
This tab allows you to view a list of identified servers on the monitored server subnets. The main table displays a list of the infrastructure devices, routers, involved in transactions to or from the server subnets and associated servers.
Devices
This tab allows you to view a list of infrastructure devices, routers, involved in transactions to or from the server subnets and associated servers.
You can select the number of items to show from the drop-down menu above the table; the default is 10 items.
Sites
Located at Configuration > Sites.
Sites are subnet and IP range aliases.
- You can assign a name to a subnet or IP range.
- GigaFlow will collect data associated with this range.
To define a new site:
- Click Configuration > Sites.
- Existing sites are displayed in the main table.
- Scroll down to create a new site.
Add Site
To add a new site:
- Enter the name of the new site.
- Enter a description of the new site.
- Enter a start IP address for the site, e.g. 172.1.1.0.
- Enter an end IP address for the site, e.g. 172.1.1.255.
- Is the traffic natted? Yes or no.
Sometimes, it can be useful to define a site by subnet and by infrastructure device. For example, a corporate network could have a subnet served by more than one router. To create a granular view of flow through each router, a separate site could be created for each router, defined by the IP range of the subnet as well as the device name. You can type to filter the device list.
To add a device to a site:
- Click to select a device to associate with the site.
- Click the up arrow
 . to associate this device with the site; the site is now defined by the IP range and the selected device(s).
. to associate this device with the site; the site is now defined by the IP range and the selected device(s). - Click Save.
Add Bulk Sites
To bulk-add new sites, i.e. more than one site at a time:
- Enter required site information using the format:
name,description,startip,endip,natted(y/n),deviceIP
- Click Save.
Use a new line for each new site.
Existing Sites
To edit a site definition, click Configuration > Sites and click on the site name or on the adjacent drill down icon ![]() . This will bring up a new page for that site where you can edit the group definition.
. This will bring up a new page for that site where you can edit the group definition.
The table of sites shows:
- Name.
- Start.
- End.
- Natted.
- Devices.
- Devices Remaining.
- Hits.
- Src Bytes.
- Dst Bytes.
- Src Pkt.
- Dst Pkt.
SNMP Discovered Subnets
To edit a site definition, click Configuration > Sites and click on the site name or on the adjacent drill down icon ![]() . This will bring up a new page for that site where you can edit the group definition.
. This will bring up a new page for that site where you can edit the group definition.
For each SNMP discovered subnet, the table displays:
- Device.
- Name.
- Device IP.
- IfIndex.
- Name.
- Subnet.
- Action.
- Alias.
- Description.
- Speed In.
- Speed Out.
- Admin.
- Oper.
System
Figure: The System Settings menu
This is where you can make changes to the system settings.
Alerting
Located at System > Alerting.
Configure GigaFlow to alert you when something happens. Syslog or mail alerts can be set up for any of the following:
- SYN Source Network Sweep: alerts if a source IP address fails to get a response from more than IP Address Count Threshold unique destination addresses.
- SYN Source Port Sweep: alerts if a source IP address fails to get a response from more than Port Count Threshold unique destination ports.
- SYN Source Network And Port Sweep: alerts if a source IP address exceeds both Port Count Threshold and IP Address Count Threshold thresholds.
- SYN Destination Unreachable Server: alerts if a destination IP address fails to respond to more than IP Address Count Threshold unique destination addresses.
- SYN Destination Port Sweep: alerts if a destination IP address fails to respond to more than Port Count Threshold unique destination ports.
- SYN Destination Network And Port Sweep: alerts if a destination IP address exceeds both Port Count Threshold and IP Address Count Threshold thresholds.
- Blacklist source.
- Blacklist destination.
- Profile exceptions.
- A device restarts sending flows.
- A device stops sending flows.
Syslog Alerts
To configure a system log alert:
- Toggle the Yes or No options for any of alert situations.
- You can set and save the server(s) address(es) below. The syslog server(s) input can have multiple entries, separated by a comma, e.g.
172.16.254.1, 172.16.254.2
- Each entry can also have a port, facility and warning level set using the format:
IP_Address:Port:Facility:Level
e.g. 172.21.40.1:515:4:23,172.21.40.2:516:23:4
- In this example, messages are sent to 2 servers; the first is on port 515 and the second is on port 516. Both are using the "Local 7" Facility and the "Warning" level. See syslog at Wikipedia for more.
- Click Save to store the server address.
- Sent alerts are displayed with the following information:
- Address.
- Port.
- Facility, e.g. Local 7.
- Level, e.g. Warning.
- Sent.
Sample Syslog Message Types
- Profiling
{"Application":"HTTPS TCP/443","Eventer":"172.0.0.1","Profile":"Facebook","appid":393659,"bytes":1447,"device":"172.0.0.1","domain":"",
"dstadd":"172.0.0.1","dstport":50561,"duration":288,"eventname":"Profiler","flags":26,"fwevent":0,"fwextcode":0,"inif":12,
"macdst":"00:00:00:00:00:00","macsrc":"00:00:00:00:00:00","outif":30,"packets":10,"proto":6,"srcadd":"172.0.0.1","srcport":443,
"time":1475147589242,"timeH":"29-Sep-2016 12:13:09.242","tos":40,"user":""}
- Blacklist
{"Application":"BitTorrent TCP/6881","Black List":"http://lists.blocklist.de/lists/bots.txt","Black List
Type":"Source","Eventer":"172.0.0.1","appid":400097,"bytes":120,"device":"172.0.0.1","domain":"","dstadd":"172.0.0.1",
"dstport":63533,"duration":1380, "eventname":"Black List
Src","flags":20,"fwevent":0,"fwextcode":0,"inif":12,"macdst":"00:00:00:00:00:00","macsrc":"00:00:00:00:00:00",
"outif":30,"packets":3,"proto":6,"srcadd"
- "172.0.0.1","srcport":6881,"time":1475147643237,"timeH":"29-Sep-2016 12:14:03.237","tos":40,"user":""}
- Syn Source
{"Application":"TCP/49755","Eventer":"172.0.0.1","Syn Type":"Source","appid":442971,"bytes":152,"device":"172.0.0.1","domain":"","dstadd":"172.0.0.1","dstport":54350,
"duration":1804,"eventname":"Syn Src Network Sweep",
"flags":2,"fwevent":0,"fwextcode":0,"inif":30,"macdst":"00:00:00:00:00:00","macsrc":"00:00:00:00:00:00",
"outif":12,"packets":3,
"proto":6,"srcadd":"172.0.0.1","srcport":49755,
"time":1475147666238,"timeH":"29-Sep-2016 12:14:26.238","tos":0,"user":""}
- Syn Destination
{"Application":"TCP/34056","Eventer":"172.0.0.1","Syn
Type":"Destination","appid":427272,"bytes":152,"device":"172.0.0.1","domain":"","dstadd":"172.0.0.1",
"dstport":34056,"duration":1124,"eventname":"Syn Dst Port
Sweep","flags":2,"fwevent":0,"fwextcode":0,"inif":14,"macdst":"00:00:00:00:00:00","macsrc":"00:00:00:00:00:00",
"outif":30,"packets":3,"proto":6,"srcadd":"172.0.0.1","srcport":57058,
"time":1475147662254,"timeH":"29-Sep-2016 12:14:22.254","tos":0,"user":""}
The IP addresses in these sample Syslog messages have been replaced with 172.0.0.1.
Mail Alerts
To configure a system email alert:
Toggle the Yes or No options for any of alert situations.
Click Save ![]() to store the server address.
to store the server address.
Netflow Event Types to Process
This table lists different possible event triggers with options to: (i) create and event and (ii) trigger a script to run.
The event triggers include:
- Netflow Unknown.
- Netflow TCA.
- Netflow Route Change.
- Netflow Immitigable.
- Netflow Bandwidth.
- Netflow Egress Measurement.
- Netflow Ingress Measurement.
Event Scripts
Original Content
Located at System > Event Scripts.
This is where you can add your own scripts to create new workflows. A table lists existing scripts with the following information:
- Script ID.
- Script name.
- Script description.
- Script length in bytes.
- Who created the script, e.g. Admin.
- Time and date the script was created.
- Is the script currently running? Yes or No.
- The memory occupied by the script.
- How many times the script has been run.
- Average runtime in milliseconds.
- The number of trigger events.
- The number of dropped trigger events.
- The trigger for the script.
- Any errors.
- Actions:
- Refresh
- Edit
- Delete
- Run
To add a script:
- Click + in the top right.
- Enter a name and description.
- Select a trigger event from the drop-down menu. Possible triggers are:
- Not set.
- 1 Minute.
- 5 Minute.
- 15 Minute.
- All ARP.
- Black List Dst.
- Black List Src.
- Daily.
- Device Restarts Sending Flows.
- Device Stops Sending Flows.
- Hourly.
- Lost Neighbour.
- New ARP.
- New Device.
- New IP.
- New MAC.
- New Neighbour.
- One Off.
- Profile Exception.
- Sys Dst Network and Port Sweep.
- Syn Dst Port Sweep.
- Syn Dst Unreachable Server.
- Syn Src Network and Port Sweep.
- Syn Src Network Sweep.
- Syn Src Port Sweep.
- Syslog.
- Enter the script in the main text box.
- All scripts are JavaScript; the engine is Oracle's Nashorn.
- Click Save .
GigaFlow Cluster
Located at System > GigaFlow Cluster.
A single GigaFlow server can be configured to search for IP addresses across many remote GigaFlow servers directly from Viavi's Apex system. This feature is useful for large organisations that may have many GigaFlow servers monitoring different networks within the organisation, e.g. in different regions. The central administrator may want a view across the entire network, e.g. to determine if a particular suspect IP address has been recorded by routers on different networks.
In this example, assume that you are the main administrator and you want visibility on several remote GigaFlow servers.
The set-up is:
- GigaFlow Server #0: this is the server at HQ, used by the main administrator. We call this the Pitcher.
- GigaFlow Server #1: this is remote GigaFlow server #1. We call this Receiver 1.
- GigaFlow Server #2: this is remote GigaFlow server #2. We call this Receiver 2.
- GigaFlow Server #3: this is remote GigaFlow server #3. We call this Receiver 3.
Figure: Defining a GigaFlow cluster
This Server
Log in to GigaFlow Server #0, the Pitcher, and navigate to System > GigaFlow Cluster.
In the This Server panel, you will see a pre-generated unique secret. Leave this as is.
In another browser tab or window, log into Receiver 1 (GigaFlow Server #1). Copy the server shared from Receiver 1's This Server panel. You do not need to do anything with the New Cluster Server panel on the receivers.
Figure: This Server panel
New Cluster Server
Switch back to the Pitcher (GigaFlow Server #0). In the New Cluster Server panel, perform the following steps:
- In the Remote Server Name field, enter the name of a server that Apex returns when you search across the GigaFlow servers (for example, Receiver 1).
- In the Remote Server Description field, enter the description that shows when you hover over the server name when you search across the GigaFlow servers, (for example, EMEA GigaFlow server Receiver 1).
- In the Remote Server URL field, enter the full IP address, including the port number, used to connect to Receiver 1, (for example, in the format
http(s)://172.1.1.0:22 ). - In the My IP Address field, enter the IP address of the Pitcher system as seen by Receiver 1.
Note:
This IP address is used by the Pitcher to generate a secure hashed key for communication. The receiver reverses this hash using, among other things, the IP address of the Pitcher. An intermediate firewall (NAT) could create problems if the Pitcher does not create the hashed key using the IP address seen by the receiver. - In the Admin User ID field, enter the UserID used when making superuser calls to Receiver 1 (for example, Admin). This is used during this set-up process.
- In the Standard User field, enter the UserID used when making report requests, (for example, reportuser). This is used by all the clients when collecting data from the receiver.
Note:
This user must exist on Receiver 1. If it does not exist, then switch to Receiver 1 and create a new normal user on Receiver 1 (for example, reportuser). - In the Server Shared Secret field, paste Receiver 1's secret (for example, the key copied from Receiver 1's This Server panel).
- Click the Add New Cluster Server button to add Receiver 1.
- Repeat this process for Receiver 2 and Receiver 3.
RESULT: The Pitcher connects to Receiver 1 using the Admin user to verify that everything is correct and to populate the table in the Cluster Access frame, on the System > GigaFlow Cluster page. Receiver 1 shows in the main table.
Figure: New Cluster Server panel
The cluster server feature is flexible, this means that a receiver in one cluster can be a pitcher for another. |
Cluster Access
The Cluster Access panel shows cluster access status. The table lists:
- ID: Cluster ID.
- Added: Time and date.
- By: User.
- Net State: network state, up or down.
- Admin State: admin status, i.e. details on its operation.
- Reporter State: success or fail.
- Settings: JSON object.
- Actions: delete.
Search the GigaFlow Cluster
Following the search link from Apex, you will be brought to a new tab and the log in screen for the Pitcher machine. After logging in, you will be brought to the GigaFlow Cluster report page. This displays a list of hits for this IP address across the cluster; in this example, the IP address might be found on devices monitored by all three receivers. Clicking on a receiver name brings up the forensics report summary for that IP address from that receiver in the table at the bottom of the summary page. Alongside each receiver on the results page is a link out to that particular server.
Figure: Conducting a GigaFlow Cluster search
See also Reports > Cluster Search.
Encryption and GigaFlow Clusters
Communication between all clients in a Gigaflow cluster is IP to IP, i.e. unicast. The traffic is routed over https, using TLS based on certificates.
Global
New icons along top.
Located at System > Global.
You can find most of the system-wide settings here.
Along the top of the page are quick links to the different settings options. These are the following:
- General
- LDAP
- SSL
- Remote Services
- SNMP V2
- SNMP V3
- Log
- Proxy
- MAC Vendors
- Storage
- Integrations
- GigaStor
- Import/Export
General
In the General settings box, you can change:
- Server name: This is the name associated with the GigaFlow server and does not have to be the same as the hostname. This is the name used when when the server calls the GigaFlow home servers. It aids identification.
- Theme: light or dark.
- Display IP on login: Yes or No.
- Max FPR Clients: This is the maximum number of First Packet Response clients supported by the system and any one point in time. 400 is the default.
- Max memory IPs: 300000 by default. This is the maximum number of IP addresses that can be cached in RAM before writing to disk. It functions as a memory table lookup for GigaFlow Search. In general, there is no need for you to change this. The aim is to reduce disk read and writes.
- SNMP Device Threads: 20 by default.
- SNMP Auto Poll Interface Threshold: 100 by default.
- TCP Testing Ports: e.g. 22, 23, 80, 443, 3389, 1143, 21.
- Capacity Planning thresholds: e.g. 30, 60, 80.
- TCP Testing Timeout (ms): 200 by default.
- TCP Port Threads: 4 by default.
- TCP Device Threads: 4 by default.
- TCP SYN Port Threshold: 5 by default.
- TCP SYN Address Threshold: 10 by default.
- Duplicate Cache Size*: 90 by default. This is the number of flows that each devices should cache in order to try and detect duplicates. It will use the start/end time, src/dst port and IP address as well as the byte and packet count to match.
- Process Duplicate Flows: Yes or No.
- Ignore Duplicates On Summaries: Yes or No.
- Process Flow POST variables: Yes or No.
by default. - Use FWEvent Field to populate Application ID: Yes by default.
- SNMP Timeout: 2000 ms by default.
- Server Discovery Limit: default is 100 servers. Server changes require a system restart.
- Server Auto Discovery Enabled: Yes or No.
- Web Session Timeout: default is 30 minutes.
- Web X-FRAME-OPTIONS: Set to SAMEORIGIN by default. Used to indicate whether or not a browser should be allowed to render a page in a frame, iframe, embed or object. Sites can use this to avoid click-jacking attacks, by ensuring that their content is not embedded into other sites.
- Cookie Same Site: Strict by default.
- HTTPS Secure Sites Only: True by default.
- Access-Control-Allow-Origin: none by default. This is a header request that states whether the response is shared with requesting code. When a site tries to fetch content from another site, the Access-Control-Allow-Origin
header specifies where the content of a page is accessible.
Note:
If you use the clustering feature of GigaFow, then make sure that the Access-Control-Allow-Origin field is set to * (asterisk) instead of the none default value, to allow the browser to access the page. - NCI IMS Server: Set to http://nci-service-auth-default-ims.nci-service-auth-default.svc/ims/ by default.
- External Web Calls: Yes by default. Yes or No.
- Compression Level: Set to 1 by default.
- Hide Quick Start Settings: Choose if you want to hide the Quick Start Settings page after each login. Set to Yes by default.
LDAP
Before you can authenticate users using LDAP or AD, you must set the LDAP (Lightweight Directory Access Protocol) server.
Examples for an LDAP server integration :
- Server address, e.g. ldap://172.21.40.189:389.
- LDAP Group DN, the branch that should be searched to return a list of groups from e.g. ou=observer,dc=viavi,dc=solutions
- LDAP Group Field, the dn of the field to return e.g. entryDN
- LDAP Group Search,the filter to use when searching for groups e.g. (&(objectClass=groupOfNames))
- LDAP Group Search Filtered, the filter to use in the users page when filterling the list of available groups e.g. (&(objectClass=groupOfNames)(cn=$FILTER))
- LDAP User DN Base, the branch from which to search users e.g. ou=users,dc=viavi,dc=solutions
- LDAP User DN Field, the DN for the users e.g. entryDN
- LDAP Users Group Field, the filed representing the users group membership e.g. memberOf
- LDAP User Filter,the filter to apply when searching for users e.g. (&(objectClass=inetOrgPerson)(uid=$USERID))
- Username, the dn of the user to bind when searching the server e.g. cn=admin,dc=viavi,dc=solutions
- Domain Name, not required for NON AD servers e.g. LEAVE BLANK
- Password, e.g. XXXXXXXXXX
- Status, i.e. if the connection is good and how many LDAP groups have been retrieved.
Examples for Active Directory server integration :
- Server address, e.g. ldap://172.21.40.189:389.
- LDAP Group DN, e.g. dc=anuview,dc=net
- LDAP Group Field, e.g. distinguishedName
- LDAP Group Search, e.g. (&(objectClass=group))
- LDAP Group Search Filtered, e.g. (&(objectClass=group)(cn=$FILTER))
- LDAP User DN Base, e.g. dc=anuview,dc=net
- LDAP User DN Field, e.g. cn
- LDAP Users Group Field, e.g. memberOf
- LDAP User Filter, e.g. (&(objectClass=user)(sAMAccountName=$USERID))
- Username, e.g. Administrator
- Domain Name, e.g. anuview.net
- Password, e.g. XXXXXXXXXX
- Status, i.e. if the connection is good and how many LDAP groups have been retrieved.
SSL
In the SSL settings box, you can view and select or change:
- Existing certificate aliases.
- Keystore location on the network or server. Leave this blank for default setting.
- Keystore password. Leave this blank for default setting.
- Click Save Keystore Settings.
Saving will restart the HTTPS service which may take up to one minute.
HTTPS Provisioning - SSL certificate generation on GigaFlow
To generate an SSL certificate for GigaFlow, perform the following steps:
If you have the possibility to create a private key file and a .p12 or a .pfx complete certificate with a password (that includes root, intermediate, and server certificates), then you can skip steps 1. to 5. and go directly to step 6.. The private key and the .p12 or .pfx files can be copied to |
- To change the current directory to the web server, that contains the keystore, perform the following steps:
- For Linux, on your VM or appliance, in the terminal prompt, run the following command:
cd /opt/ros/resources/preposNote:
You can later make sure that the created files have the same chown/chmod permissions as the previous files, respectivelyroot/root and/orgigaflow/viavi . - For Windows, change the folder to
C:\GigaFlow\Flow\resources\prepos .
- For Linux, on your VM or appliance, in the terminal prompt, run the following command:
- To set the SAN (Subject Alternative Name) field in the CSR (Certificate Signing Request), create or edit the .cnf file as required for the target system. Use the following example to fill the .cnf file.
Note:
You must fill the fields in italic font with company specific information, especially if seen in the certificate creation section on the customer side.[ req ]
default_bits = 2048 (another option: 4096)
distinguished_name = req_distinguished_name
req_extensions = req_ext
[ req_distinguished_name ]
countryName = Country Name (2 letter code)
stateOrProvinceName = State or Province Name (full name)
localityName = Locality Name (for example, city)
organizationName = Organization Name (for example, company)
commonName = Common Name (for example, server FQDN or YOUR name)
[ req_ext ]
subjectAltName = @alt_names
[alt_names]
DNS.1 = 5l60p12.ds.jdsu.net
DNS.2 = (name without FQDN .com)
DNS.3 = (can use the IP) - To generate the public/private keypair and CSR using the .cnf file, use the following example:
openssl req -out gigaflow1_20240129.csr -newkey rsa:2048 -nodes -keyout gigaflow1_20240129.key -config gigaflow1.cnfNote:
The file created with the-keyoutcommand, *.key will be used later. - Submit the CSR to the CA (Certificate Authority). The CA will generate the cert file.
- Collect the cert file from CA.
- If possible, get a complete chain from the customer or create a password protected P12 chain from the CA files, the cert file, and the private key.
- If CA provides a *.pem file that contains all 3 sections, then use that file.
- To create a file with separate .cer files from CA, follow the below example:
cat <signed_cert_filename> <intermediate.cert> [<intermediate2.cert>] > GigaFlow1_20240129_chain.txt{.pem}
- To create a .p12 certificate used for the server, follow the below example:
openssl pkcs12 -export -in GigaFlow1_20240129_chain.txt -inkey <private_key_filename> -name 'GigaFlow1_20240129' -out GigaFlow1_20240129.p12The command requires the following parameters and will ask (also confirm) for a .p12 password to be created then used later in GigaFlow (no password fails inside GigaFlow):
in - use the certificate from CA .pem or chain of separate .txt files (.pem).
inkey - use the key created above in step 3. (.key).
name - use the DNS name of the server.
out - the name of the files to be used by GigaFlow (.p12).Example:

- In the GigaFlow UI, under System > Global > SSL, select the newly created .p12 files.
Note:
If the certificate is valid, then https shows again and the SSL page shows the certificate alias(es). This way your GigaFlow https connection is now secured.Note:
If the certificate is invalid or the file change does not work, then the https connection is refused and the GigaFlow UI will freeze.
In this case use an http connection to change the Keystore Location back toresources\prepos\roskeystore.jks and enter as Keystore Password the stringcashelros254. A new certificate needs to be created and tested.- To register the new certificate connect using http to port
7902or at the appliance Web UI, since next step can disconnect the https connection. - In the Keystore Location field enter the name of the new certificate that needs to be present in the prepos directory.

- In the Keystore Password enter the matching password (no password will not work).
Note:
GigaFlow will auto-restart the https listener to immediately use the new certificate. You are not required to manually restart the server and/or the service.Note:
The method used here may depend on the format in which the certificate(s) is/are provided by the CA. - Install the P12 into the following folders:
- For Linux:
/opt/ros/resources/prepos on the GigaFlow server. - For Windows:
C:\GigaFlow\Flow\resources\prepos on the GigaFlow server.
- For Linux:
- Adjust the file chmod/chown attributes on the P12 to match the previous .p12 file.
- To register the new certificate connect using http to port
Remote Services
ZeroMQ
- Status: default, Not Configured.
- Listener: default, '*.5555.
- Cache Period (milliseconds): default, 60000.
- Cache Size: default, 100000.
- Max Flows Transmitted Per Message: default, 100000.
- Max Seconds Per Message: default, 60000.
- Message Store:
- Restart required.
- Message Store Max Size MB: default, 50000.
Save ZeroMQ Settings.
Observer GigaStor
- URL.
- Display.
- User Name.
- Password.
- Status.
- Actions.
Kafka
- Status: No status for now.
- Broker: enter the Kafka broker address.
- SSL Trust Store: path to trust store.
- Trust Store Pass: password.
- Topic: default, gigaflowraw.
- Group ID: group name.
- Cache Period (milliseconds): default, 300000.
- Cache Size: 5000.
Save Kafka Settings.
Syslog Forensics
- Status: for example, has sent w packets , x dropped, y largest, z, longest t (ms).
- Format: Text or JSON.
- Storage Buffer: 10000.
- Server: IP address and port in the format xxx.xxx.xxx.xxx:xx
- A change requires a restart to affect all devices.
- Cache Period (milliseconds): 300000.
- A change requires a restart to affect all devices.
- Cache Size: 5000.
- A change requires a restart to affect all devices.
Save Syslog Settings.
SNMP V2 Settings
Click the first icon from the left, above the main tabs, to add an SNMP v2 Settings Community.
- Enter the community name in the text box and click Save.
SNMP allows GigaFlow to poll sending devices. GigaFlow supports multiple concurrent pollers. Each device is serviced every 30 minutes. SNMP polling is used to retrieve:
- Device information, i.e. location, sysOID, interface names, descriptions, aliases and IP addresses.
- ARP table for IP address to MAC address to interface mapping.
- CAM table for MAC to switch port mapping.
In the SNMP V2 settings box, you can add or delete new SNMP V2 community strings. To add or delete a community string:
- Delete existing communities by clicking the delete icon.
SNMP V3 Settings
Click the second icon from the left, above the main tabs, to add an SNMP v3 Settings Commuity.
- Enter a user name.
- Select the Authentication Type. Choose one of the following secure hash functions:
- MD5
- SHA
- HMAC128SHA224
- HMAC192SHA256
- HMAC256SHA384
- HMAC384SHA512.
- Enter an authentication type password.
- Select the Privacy Type. Choose one of the following encryption standards:
- AES-128
- AES-192
- AES-256
- AES-192-3DES
- AES-256-3DES
- DES
- 3DES.
- Enter a privacy password.
- Enter a context. SNMP contexts provide VPN users with a secure way of accessing MIB data. See Cisco and the Glossary for more.
- Click the Save button.
SNMP allows GigaFlow to poll sending devices. In the SNMP V3 settings box, you can view and delete SNMP v3 community strings.
Log Setting
In the Log settings box, you can view the log file and change the logging level:
- Click on Log File to view the log file entries.
- Select a logging level from the drop-down menu, i.e. DEBUG, INFO, ERROR, FATAL, WARN.
- Click Save to save changes to the logging level.
Proxy Setting
These are the proxy settings used to access GigaFlow's homeworld server. The information is required for several reasons: (i) to allow GigaFlow to call home and register itself; (ii) to let us know that your installation is healthy and working; (iii) to update blacklists. All calls home are in cleartext. See System > Licences for more.
- Server ID. This is the unique server ID; it is sent in calls home.
- Proxy address. Leave blank to disable proxy use.
- Proxy port, e.g. 80.
- Proxy user.
- Proxy password.
- Click Test Proxy Settings to test the proxy server.
- Click Save Proxy Settings to save the settings.
MAC Vendors
Click the fourth icon from the left, above the main tabs, to add a MAC Vendor. To add a new vendor prefix:
- Enter a MAC address.
- Enter the prefix length in octets, i.e. 12 for the full address, 10 leftmost octets, 8 leftmost octets, 6 leftmost octets or 4 leftmost octets.
- Enter the vendor name, e.g. Dell.
- Click Save to save changes.
Existing vendor prefixes are displayed in the table below alongside the date created and available actions, i.e. modify or delete.
Mail Settings
If you are using email alerts, you can configure email here. To set up email:
- Change Enabled from No to Yes.
- Enter the email address that GigaFlow will send email from.
- Enter the email address of the user receiving GigaFlow alerts.
- TLS (transport layer security)? Yes or No. See Glossary for more about TLS.
- Enter the mail server username.
- Enter the mail server password.
- Enter the mail server address.
- Enter the mail server port number, e.g. 25.
- Click Test Mail Settings to test the email server.
- Click 'Save Mail Settings to save changes.
Storage
In the Storage settings box, you can make changes to the following settings:
- Monitor Drive Space: enable or disable drive space monitoring, i.e. Yes or No.
- Drive To Monitor: set the drive to monitor, e.g. C:/.
- Min Free Space (GB): set the minimum free space allowed (GB).
- Default Device Storage Space (GB): set the default device storage space (GB).
- Min Forensics Storage (Days): set the minimum forensics storage in days, for example 21. After this time, flowsec records will be deleted.
Default value: 2
Requires 720 MB or 15 per hour.
See Disk Usage by Device, below. - Max Forensics Storage (Days): set the maximum forensics storage in days, for example 60.
Default value: 30
Under this field the following deletion details are shown:
Note:
Make sure that the number of days in the Max Forensics Storage (Days) field is larger than the one in the Min Forensics Storage (Days) field.
- IP Search Storage (Days): set the IP search storage (Days), e.g. 21. After this time, IP address history will be deleted.
- Forensics Storage Threads:
- Forensics Table Cache Size: set the forensics table cache size, e.g. 10,000. This is the number of entries cached before writing to disk.
- Forensics Table Cache Age (ms): set the forensic table cache age (milliseconds), e.g. 10,000. After 10 seconds, the forensic data is written to disk.
- Forensics Cache Storage: set the forensic cache storage size, e.g. 40,000.
- Forensics Indexes: enter forensics indexes. This is a comma-delimited list of forensics table field names, e.g. "srcadd,dstadd,appid". See Reports > Forensics in the Reference Manual for more.
- Enter forensics indexes
- Forensics Rollup Age (Days): set the forensic rollup age (Days), e.g. 4 days, period after which data should be rolled into daily tables.
- Forensics Rollup Location: set the forensics rollup location.
- Event Storage Period (Days): set the event storage period (Days), e.g. 100 days, how long events should be recorded for.
- ARP Storage Period (Days): set the ARP storage period (Days), e.g. 100 days, how long ARP entries should be recorded for.
- CAM Storage Period (Days): set the CAM storage period (Days), e.g. 100 days, how long ARP entries should be recorded for.
- Event Summary Storage Period (Days): set the event summary storage period (Days), e.g. 200 days.
- Interface Summary Storage Period (Days): set the interface summary storage period (Days), e.g. 200 days.
- DB Fetch Size:
- Allow Unlogged flow tables:
- Auto-tune PostgreSQL: enable or disable Auto Tune of the Postgres database. Yes or No.
- Archive Folder Location:
- Enter Archive Folder Location
- Archiving Enabled :
- TCP Syslog Threads:*
- TCP Syslog Buffer Size*
To commit changes, click Save Storage Settings.
Disk Usage by Device
The following information is given for each flow device:
Netflow
- Device: device name.
- Largest Time: date and hour.
- File Window: hours.
- Total MB.
- % of All.
- Average File MB.
- Average Per Day MB.
- Largest Size.
Data Retention and Rollup
The minimum Forensics Storage is 21 days. Forensics data is stored in tables for up to four hours to speed up search and reporting. These tables are rolled into one-day tables after the Forensics Rollup Age period; this is four days by default. (see System > Global.) This is a minimum period.
It is important to set aside space for drive monitoring. GigaFlow will fill the disk drives until the pre-defined minimum amount of free space is left. GigaFlow caps the storage that any particular device is using for forensics data; this is 50 GB by default. This cap can be changed globally and on a per device basis which in turn sets an overall cap on the amount of space used by GigaFlow.
| Type | Resolution | Table Duration (default) | Retention | Setting Involved |
|---|---|---|---|---|
| Raw Flows | millisecond | 1 hour-1 day | 21 days | Min Free Space, Default Device Storage Space, Min Forensics Storage, Forensics Rollup Age. |
| IP Search | millisecond | 1 day | 21 days | IP Search Duration. |
| Events | millisecond | 4 hour | 100 days | Event Storage Period, Event Summary Storage Period. |
| ARP | millisecond | 1 day | 100 days | ARP Storage Period. |
| CAM | millisecond | 1 day | 100 days | CAM Storage Period. |
| Interface Summaries | Minute | 2 day | 200 days | Interface Summary Storage Period. |
| Traffic Summaries | Hour | 7 day | 200 days | Interface Summary Storage Period. |
Integrations
An integration allows you to call defined external web pages or scripts directly from the Device Interface Overview page. To add an integration, navigate to System > Global. In the Integrations settings box, you can add or change an integration.
There are two types of integration:
- Device: where you can pass the device IP address.
- Interface: where you can pass the device IP address and the ifIndex of the interface being used.
To add an integration:
- Click on the Add Integration icon, fifth from left at the top of the page.
- Enter a new name, e.g. "Interface Action 1".
- Select the type of target, i.e. a device or an interface. These map to the IP address of the device and the ifIndex of the interface.
- Select the type of action, i.e. will the integration work with a web page or a script.
- Enter the web page URL or select a script.
- Enter inputs to be passed via the website or script.
- Click Save to save changes.
Example 1
In the code below, the populated field tells the software that you want to populate the device field with the IP address and the ifindex field with the ifindex. These fields (device and ifindex) will be passed to the target. We also have required fields, which are fields which the user is required to populate.
{
'populated':{
'device':'flow_device',
'ifindex':'flow_ifindex'
}, 'required':[
{'name':'user','display':,'type':'text','value':},
{'name':'password','display':'Password','type':'password'},
{'name':'macro','display':'What Macro?','type':'select','data':['macro1','macro2','macro3','macro4']}
] }
Example 2:
- Web URL http://www.example.com/?device=flow_device&interface=flow_ifindex
- This script prints the collected information. It then runs dir and outputs the results.
var ProcessBuilder = Java.type('java.lang.ProcessBuilder');
var BufferedReader = Java.type('java.io.BufferedReader');
var InputStreamReader= Java.type('java.io.InputStreamReader');
output.append(data);
output.append("Device IP:"+data.get("device")+"
");
output.append("IFIndex:"+data.get("ifindex")+"
");
try {
// Use a ProcessBuilder
//var pb = new ProcessBuilder("ls","-lrt","/"); //linux
var pb = new ProcessBuilder("cmd.exe", "/C", "dir"); //windows
output.append("Command Run");
var p = pb.start();
var is = p.getInputStream();
var br = new BufferedReader(new InputStreamReader(is));
var line = null;
while ((line = br.readLine()) != null) {
output.append(line+"");
}
var r = p.waitFor(); // Let the process finish.
if (r == 0) { // No error
// run cmd2.
}
output.append("All Done");
} catch ( e) {
output.append(e.printStackTrace());
}
log.warn("end")
GigaStor
In this tab you can:
- Click Add GigaStor
 . This is the last icon from the top-right of the page.
. This is the last icon from the top-right of the page. - Enter the following information:
- Display Name
- IP Address
- User
- Password
- Click Save.
The new GigaStor will appear in the list of Existing GigaStors.
Choose how you want to use the Trace Extraction functionality from the options under Allow Trace Extraction:
- Always allow: enables Trace Extraction in GigaFlow interface.
- Allow if no Apex: enables Trace Extraction in GigaFlow only if there is no integration with Observer Apex.
- No: disables the Trace Extraction functionality.
For more information on Trace Extraction, refer to Extract a GigaStor trace file.
View and configure the GigaStors you have added:
- You can change the Display name, User name and Password.
- After each edit, click the corresponding Save icon.
- You can check the GigaStor status.
- To delete a GigaStor, click the corresponding Delete icon, then confirm.
Import/Export
In this tab you can perform the following actions:
- Import GigaFlow system settings and configuration.
- Export GigaFlow system settings and configuration.
The Import/Export feature allows you to easily import or export the following GigaFlow system settings and configuration:
- Named Ports
- Flow Objects
- Defined Applications
- Profiles
- Defined Services
- General Settings
- Storage
- Syslog Parsers.
A typical use case for this functionality is exporting the settings configured on an existing GigaFlow server to import them on a newly deployed GigaFlow server.
Since defining Profiles and Flow Objects can be time intensive, the
Import/Export feature provides an error free mechanism to replicate the definitions.
To import the GigaFlow configuration and system settings, perform the following steps:
- In the Import frame, click the Choose File button.
- In the popup window, browse a previously Exported file.
- Click the Import button.
The selected .json file is uploaded to the server in theconfigsettingsfolder, under your GigaFlow installation folder.
The Successfully imported settings message shows below the Import button. - If the import process was unsuccessful, then a descriptive error message shows.
Correct the error accordingly and try again. - To enforce the import operation, perform a system restart.
The import action replaces the previous GigaFlow configuration and system settings. |
- To export the GigaFlow configuration and system settings, perform one or more of the following steps:
- Mark the Select All checkbox, to export the configuration and system settings listed in the steps below.
- Mark the Named Ports checkbox, to export the user defined protocols/ports and application names. See Configuration > Applications > Existing Protocol/Port Applications.
- Mark the Flow Objects, Defined Applications, Profiles checkbox, to export the following settings and/or configuration:
- Flow objects, that are logical sets of flows comprised of defined flows, IP sources, and destination addresses. They are listed under the Configuration > Applications > Existing Flow Objects frame.
- Defined applications exports all the applications listed under the Configuration > Applications > Existing Defined Application frame.
- Profiles exports all the profiles listed under the Configuration > Profiling > Existing Profilers frame. For each profile the Entry and the Allowed flow objects are exported.
- Mark the Defined Services checkbox, to export the services listed in the Configuration > Applications > Existing Defined Service tab. Defined Services are identified by an IP address, or port(s), or both, and, optionally, a protocol.
- Mark the General Settings checkbox, to export the settings configured in the System > Global > General tab.
- Mark the Storage checkbox, to export the settings configured in the System > Global > Storage tab.
- Mark the Syslog Parsers checkbox, to export the patterns configured in the System > Syslog Parsers tab.
- Click the Export button.
The export of the system configuration and settings results in a user-readable file (.json format). The file is downloaded automatically to the default download folder of the browser.Note:
If you open the .json file, then make sure not to delete the"Metadata"section. This section contains the version of the GigaFlow instace from which the export was done.
Licenses
Located at System > Licenses.
Here you can view all the licences associated with GigaFlow.
GigaFlow License
The GigaFlow License table lists:
- This Server ID.
- First run, date and time.
- Customer name.
- Product name.
- Expiration date of license.
- Duration of license.
- Number of flow devices.
- Number of flows per second.
- You can enter a new license in the text box at the end of this table. Click ADD to submit.
The license is also viewable as a JSON object at the bottom of the page.
3rd Party Licenses
All 3rd party licenses are listed in the next table. These are:
Cleartext Communication
All communications between your installation of GigaFlow and our servers are carried out in cleartext over HTTP; you have complete visibilty. You can view call home data at System > Licenses.
Call Home Send
All communications between your installation of GigaFlow and our servers are carried out in cleartext; you have complete visibilty. You can view call home data at System > Licenses.
Call Home Response
A typical response to a call home might look like. You can view call home response data at System > Licenses.
Call Home Errors
You can view all call home errors at System > Licenses.
License
JSON object version of GigaFlow license.
Receivers
Add Port and Netflow Processing Threads links at top of page.
Located at System > Receivers.
Here you can view and edit GigaFlow's defined Netflow receivers.
It is important to ensure that the installation is ready to listen. Senders on your network will be configured to send to the GigaFlow server address and to a defined port; these must match the receivers.
GigaFlow is built to receive and process flow records and session-based syslogs. GigaFlow can also process syslog messages relating to specific user or IP authentication details.
Flow records are processed automatically into the flow databases. The records are also checked against blacklisted IPs and against defined Profilers. See System > Blacklists and Profiling.
The syslog messages are sent to the syslog processor for parsing.
Existing Ports
In the Existing Ports table you can see the existing listener ports available and if they are receiving flows or syslogs.

You can select the number of ports to show from the dropdown menu above the table (for example, 10, 25, 50, 100 or all). The default value is 50 items. The total number of ports is displayed at the top of the table. The displayed information includes the following columns:
- Port
Displays the receiver port number. - Type
Displays the receiver port type. See the Add Port section. - Certificate details
Displays the details of the certificate uploaded for the particular Syslog TCP Encrypted port. If a chain certificate is involved, then the cell displays the details of all certificates from the child to the root CA (Certificate Authority). - Settings
Shows the subnet mask applied to the IP address of the source device.Note: This can be useful to consolidate multiple flow senders into virtual source device(s). Leave the field blank for no summarisation. - Packets
Displays the number of packets received on the configured port. It resets after every 10000 packets. - Packet process time (ns)
Min, Avg, Max over 10000 packets
Displays the minimum, average, and maximum times in nanoseconds for processing a packet. The values are computed for every 10000 packets. - Running
Indicates if the receiver is up and ready to receive packets. The related statuses are:- Yes
- No.
- Actions
- To stop the receiver port, click the corresponding Stop
 button on the related row, then confirm.
button on the related row, then confirm. - To remove the receiver port, click the corresponding Delete button on the related row, then confirm.
- To stop the receiver port, click the corresponding Stop
Add Port
To add a new port, click the + icon at the top of the page. Then:
- Enter the new port number.
- Enter the new port type. You can add the following types of ports:
- Netflow/IPFix/JFlow/SFlow
- Netflow TCP
- Syslog TCP
- Syslog
- Syslog TCP Encrypted - see Add a Syslog TCP Encrypted receiver procedure.
- JSON.
- Enter the new port source mask. This mask is applied to the IP address of the source device. It can be useful to consolidate multiple flow senders into virtual source device(s). Leave blank for no summarization.
- Click Save to create and save.
Add a Syslog TCP Encrypted receiver
To add a Syslog TCP Encrypted receiver, perform the following steps:
- Login to GigaFlow.
- In the GigaFlow UI, go to the System > Receivers page.
- In the upper-right corner, click the Add Port + button.
The ADD PORT dialog shows. - In the Port field, enter the port number for the receiver.
- In the Type drop-down list, select the Syslog TCP Encrypted port type.
The TLS Certificate and Private key file file browse fields show at the bottom of the ADD PORT dialog. - In the Source mask field, enter the mask you want to apply to the IP address of the source device.
Note: This can be useful to consolidate multiple flow senders into virtual source device(s). Leave the field blank for no summarisation. - In the TLS Certificate file browse field, click the Choose File button to upload the TLS Certificate file used to decrypt the syslogs.
Maximum file size: 200KBNote: The TLS Certificate file must be in an unencrypted Privacy-Enhanced Mail (PEM) format. - If the Private Key is in a separate file, then in the Private key file file browse field, click the Choose File button to upload the related private key.
Maximum file size: 200KBNote: The Private key file must be in an unencrypted Privacy-Enhanced Mail (PEM) format. - Click the Save Button.
A Certificate text box is shown below the message, containig the following 2 fields related to the uploaded certificate:
|
|
Netflow Processing Threads
To edit the number of Netflow processing threads, enter the new number and click Save.
Port Threads
The Port Threads table displays summary information about the port threads. This includes:
- Port number.
- Type, e.g. V5, V9.
- Thread.
- Devices.
- Received packets.
- Dropped packets.
- Current packets.
- Ignored packets.
- Max packets.
Syslog Parsers
Infrastructure visibility is achieved using session-based Syslog. Located at System > Syslog Parsers.
System log parsing rules can be viewed and edited here.

You can create a new syslog parser pattern in 2 ways. Use the + New Pattern button on the All Patterns widget, or the + button on a row in the Exceptions widget.
All Patterns
All the existing syslog parser patterns are listed in the All Patterns table. The displayed information includes the following columns:
- ID
The ID of the listed pattern. This should be a negative number and unique to each pattern. - Name
The display name for the listed pattern. It can also be empty or a duplicate. - Description
The description of the listed pattern. - Type
The pattern type for the related row. The types of the patterns can be as follows:- User - only the fields required to populate GigaFlow's User to IP address functionality can be populated.
- Session - the available forensics fields (including User) can be populated.
- Syslog Script - the available fields are sent to the scripting engine for further processing.
- Fields
Lists how many fields have been selected and are used to populate GigaFlow by this parser. - Matching Time(ms)
Shows how long it took, in milliseconds, to use the current parser successfully with the current test data to perform1000 matches. - Parse Others Time(ms)
Shows how long it took, in milliseconds, for this parser to match the other available test data (from the other configured parsers) to perform1000 matches (successful or otherwise). - Actions
- To edit the pattern on the related row, click the Edit syslog parser pencil button.
- To delete the pattern on the related row, click the corresponding Delete button, then confirm.
- Error indicator
A red error badge shows next to a parser that has runtime parse errors. Open the parser in the Edit Pattern dialog to see the errors.
If either the Matching Time(ms) or Parse Others Time(ms) times are high, then this will have a negative effect on the syslog ingest rate and may prompt a change of matcher or a re-ordering of rules to lessen its impact (improve the ingest performance). |
To create a new syslog parser pattern, click the + New Pattern button in the upper-right corner of the All Patterns widget. The New Pattern dialog shows.

- In the Paste sample syslog data field, paste a sample syslog message.
- Click the Create & Edit button.
The Edit Pattern dialog shows. The pasted message is pre-filled in the Test Data field.
Note:
To close the dialog without creating a pattern, click the Cancel button.
You can also create a pattern from an unmatched message. In the Exceptions widget, click the New pattern from this exception + button on the related row.
The Edit Pattern dialog contains the following fields:
- Name - the display name for the pattern.
- Description - the description for the pattern.
- Type - the pattern type: User, Session, or Syslog Script.
- Mode - the pattern editing mode: Manual or Visual Builder.
- Test Data - one or more sample syslog messages used to build and test the pattern.
- Pattern - the regular expression (regex) used to match syslog messages and extract fields.
Below these fields, the Matches table shows each matched Entry, its assigned Field, and the extracted Value. The Match Time(1000) and Match Others Time(1000) values show the time, in milliseconds, to perform 1000 matches.

Editing modes
The Mode toggle sets how you build the pattern:
- Manual - enter and edit the regex pattern directly.
- Visual Builder - build the pattern visually from the sample data. This is the default mode for a new pattern.
If you switch modes after you make changes, then a confirmation dialog warns you that you can lose those changes. |
Auto-detect fields
In Visual Builder mode, click the Auto-Detect Fields button to highlight the fields in the Test Data automatically. GigaFlow detects key=value and key:value formats, with or without spaces around the delimiter. Trailing semicolons are removed. A banner shows how many fields were auto-detected and how many are unmapped.

If you click Auto-Detect Fields again, then GigaFlow discards your manual highlights and detects the fields again. |
Selections
Each highlighted field shows as a row in the Selections table, with the following columns:
- # - the color-coded index of the selection. The same color highlights the matching text in the Test Data.
- Text - the highlighted text from the sample message.
- Field - the GigaFlow field to populate. The drop-down list is alphabetical. An already-assigned field shows as (used in #N).
- Capture Type - the regex token used to capture the value.
- To remove a selection, click the red × button on the related row.

The Capture Type drop-down list sets how GigaFlow matches the value:
- Auto-detect
- Non-whitespace (\S+)
- Digits (\d+)
- IP Address
- Any (.+?)
- Any greedy (.+)
- Word (\w+)
- Custom... - enter your own regex.

An aggressive capture type, such as Any greedy (.+), can increase the match time. |
You can also select fields manually in the Test Data area:
- Click and drag, or double-click, to highlight a text segment.
- Drag over an existing highlight to extend it, drag within a highlight to shrink it, or drag across several highlights to merge them.
The Auto-Detect Fields button adds only the detected key-value fields to the pattern. To include other text, highlight it manually. |
Additional fields
The Field drop-down list includes these fields:
- Src VLAN and Dst VLAN - populate the source and destination VLAN columns in the forensics report.
- Custom Metadata... - map the value to a custom metadata field. Enter a meta key (for example, action or category), then select the value type:
- String
- Integer
- Decimal
Custom metadata values are stored as keyed entries in the flow record.
Patterns
The Pattern field shows the regex that GigaFlow generates from your selections. It updates in real time as you change the selections.
To test the pattern, click the Test Pattern button. You can paste additional syslog lines to test against, one per line. The result shows Match or No match for each line, with a Group, Field, and Value table. A group that is not assigned to a field shows as unmapped.

Error tracking
Each parser tracks up to 100 recent parse failures. When runtime errors exist, a red error badge shows next to the parser in the All Patterns table. The Edit Pattern dialog shows an error table for that parser. Each row shows the time, the error message, and the syslog data that caused the failure.
To reset the tracked errors, click the Clear Errors button in the Edit Pattern dialog. After you fix the pattern and save it, the errors do not return. If the pattern is still incorrect, then new errors appear as more syslog messages are ingested.
Default Patterns
Default system Syslog parser patterns are listed here. These patterns match incoming syslog messages in real time. Information displayed includes:
- ID.
- Name.
- Description.
- Hits.
- Misses.
- Took.
- Actions
- To reorder a parser, click Move to the top, Move up, Move down, or Move to the bottom.
- To edit a parser, click the Edit syslog parser pencil button.
- To delete a parser, click the corresponding Delete button, then confirm.
The order of the parsers sets the match priority. When a syslog message matches a parser, the parsers below it are not checked. |
To add a parser, select it in the Parser drop-down list, then click the Add the selected default syslog parser + button. An unnamed parser shows as its ID followed by (no name set) in the list.
To reset the Hits, Misses, and Took counters, click the Clear syslog parser counters refresh button in the upper-right corner of the Default Patterns widget.
Network Address Translation (NAT) Patterns
Network Address Translation is a method of remapping one IP address space into another by modifying the network address and port information in the IP header of packets while they are in transit across a traffic routing device.
If available in a NetFlow record, then GigaFlow will automatically ingest NAT fields. To allow the ingestion of Syslog flow records which contain session or NAT fields, enable a syslog receiver in GigaFlow using the System > Receivers dialog to receive those messages. Then, to configure the required Syslog Parsers, perform the following steps:
- To add a NAT pattern, go to the System > Syslog Parsers dialog.
- In the Exceptions table, click the + button related to the syslog message for which you want to create a pattern.
This table shows the first 10 syslog messages which currently don't have a matching pattern.
A related new entry is added to the All Patterns table for the selected syslog message.
- In the All Patterns table, Actions column, click the Edit syslog parser pencil button related to the new added entry.
The Edit Pattern dialog shows.

- In the Name field, enter the name of the pattern that you want to add.
Possible values: alphanumeric ASCII characters string
Default setting: empty field - In the Description field, enter a description for the pattern.
Possible values: alphanumeric ASCII characters string
Default setting: empty field - In the Type drop-down list, select the Session pattern type.
- In the Test Data field, you can find the syslog message that you just added from the Exception table.
- In the Pattern field, enter a regular expression (regex) which will separate all of the components and the syslog message into individual elements (for example, IP address, or port number).
Note:
If the pattern is correct, then the Matches table is populated with the resulting number of entries. - For each Field type you can now assign the matching field Value:
- In the Field colum select the fields used for source or destination IP addresses and ports to track NAT or Proxy devices:
- Src IP NAT
- Src IP & Src NAT IP
- Dst IP NAT
- Dst IP & Dst NAT IP
- Src Port NAT
- Src Port & Src Port NAT
- Dst Port NAT
- Dst Port & Dst Port NAT
- Session ID
The Session ID field was added but the users will not typically utilize it. GigaFlow creates a unique Session ID for all NAT records. When a flow or a syslog record indicates a NAT translation, each forensic flow that is created receives a unique ID that links them together.
Note:
If the syslog contains a session ID, then also select the Session ID field. - In the Value column enter the value matching the related field type.
- Click the Save button.
- In the Name field, enter the name of the pattern that you want to add.
- In the Default Patterns dialog, add the created pattern as follows:
- In the Parser drop-down list select the name of the pattern that you want to add.
- In the right side of the Parser drop-down list, click the + button.
Note:
When you add a pattern in the Default Patterns table, you enable it and it is then used to match syslog messages as they are ingested in real time.
Once flows are ingested using the pattern, you will find the NAT device(s) in the Configuration > Infrastructure Devices dialog. Here you can see all the devices that GigaFlow is receiving NAT data for. If the Nat column is marked as true, then the related device is available in the NAT Reporting dialog.
Exceptions
Unmatched Syslog messages are listed here. GigaFlow groups them by signature. It replaces the variable parts of a message (such as timestamps, IP addresses, and numbers) with <*> placeholders. Similar messages then form one group.
GigaFlow keeps up to 200 groups, with up to 10 sample messages and 50 unique source IP addresses per group. The displayed information includes the following columns:
- Count - The number of messages in the group.
- Signature Pattern - The normalized signature, with the variable parts shown as <*>.
- Sources - The source IP addresses for the group (for example, 2 IPs).
- Last Seen - The time the most recent message in the group was received.
To expand a group and see its sample messages, click the related row. Each sample shows its source IP address and the time it was received.
From the Exceptions widget, you can do the following:
- To create a parser from a message, click the New pattern from this exception + button. The Edit Pattern dialog opens in Visual Builder mode, with the message pre-filled.
- To remove one group, click the Remove this exception group button on the related row, then confirm.
- To remove all groups, click the Remove all exceptions button in the upper-right corner of the Exceptions widget.
System Health
Located at System > System Health.

On this page you can find the following timelines:
- DNS cache size
The number of DNS entries currently in the GigaFlow DNS cache.
You can clear this cache using the trash icon on the System > System Status > Stats > DNS Cache entry. - All users size
The number of User entries currently in the GigaFlow cache of Username as discovered from all sources. - Users To IP Size
The number of User to IP address entries currently in the GigaFlow cache used for mapping users to up addresses in the forensics database.
You can find these entries in the System > System Status > Stats > Users Seen / Users Seen To IP links. - Forward Event Codes Size
The number of Forward Event Codes entries currently in the GigaFlow cache used for mapping these event names to their unique numeric IDs in the forensics database.
You can find these entries in the System > System Status > Stats > Event Codes links. - Forward Extended Codes Size
The number of Forward Extended Codes entries currently in the GigaFlow cache used for mapping these extended event names to their unique numeric IDs in the forensics database.
You can find these entries in the System > System Status > Stats > Ext Codes links. - Deduplication Size
The number of forensics entries cached so that they can be deduplicated in real-time. - Free Swap Space Size
The amount of free swap space available in MB. - Total Physical Memory Size
The amount of physical memory available in MB. - Committed Virtual Memory Size
The amount of virtual memory in MB that is guaranteed to be available to the running process in bytes, or -1 if this operation is not supported. - Free Physical Memory Size
The amount of free physical memory available in MB. - Total Swap Space Size
The total amount of swap space used in MB. - Total Vs Free Physical Memory Size
The amount of physical memory MB.
The amount of free physical memory MB. - Total Used Java Memory Size
The amount of memory used by GigaFlow. - CPU Load
Java Load - therecent CPU usage for the Java Virtual Machine process as a percentage across all CPUs.
System Load - therecent CPU usage for the whole system as a percentage across all CPUs. - Flows Per Second
The total number of flows per second ingested into GigaFlow from all sources. - Database Drops
The total number of drops into the GigaFlow database. A value different from 0 usually indicates an overtaked storage system, as flows cannot be saved to disk quickly enough before the RAM cache starts to run out.
You can find more details on the drops in the various tables under System > System Status > Stats. - Receiver Drops
The number of flows dropped across all NetFlow receivers. - Receiver Ignored
The count of flows which have been ignored by GigaFlow. The reasons for ignores include the following messages:- Unknown flow type
- No flow decoder - no template has been received.
- Non flow data - for example, GigaFlow does not store telemetry data or interface counters.
- Syslog Receiver Drops
The number of syslogs that were dropped because the ingest queue was full. - Syslog Receiver Queue
The size of the ingest queue for syslog messages.
You can also view this under the System > Receivers > Syslog Threads section. - ZMQ Drops
The number of flows dropped while updating the ZMQ files (that are used by Observer Apex). - Kafka Drops
The number of messages dropped while they are sent to a Kafka queue. - Free Disk Space
The amount of free disk space available in GB.
System Status
Located at System > System Status.
Log File Viewer
- Limit: 25 is the default number of items to show. Other options are None, 10, 25, 50, 100, 200, 500 and 1,000.
- Refresh: 5 seconds is the default refresh time. Other options are Never, 1 second, 5 seconds, 10 seconds, 30 seconds and 1 minute.
- You can enter a regular expression to filter log entries.
- Click Submit to update the log file viewer settings.
Memory
This page displays memory performance. The start time and uptime are displayed prominently at the top of the page.
The main table lists:
- IPs, active and total.
- IP window, e.g. 0 seconds.
- Used memory (bytes).
- Total memory (MB).
- Number of devices.
- Number of MACs.
- Maximum memory (MB).
- Percent memory used.
- Free memory (MB).
- Number of MACs For Prefix 6. Click List to list them.
- Number of MACs For Prefix 7. Click List to list them.
- Number of MACs For Prefix 9. Click List to list them.
- Number of MACs For Prefix 12. Click List to list them.
- You can go to relevant sections of the Log Viewer and to First Packet Response by clicking the links below. See System > System Status and Configuration > Server Subnets for more.
Stats
The Stats sections details:
- Number of devices.
- Latest flows per second.
- Average flows per second.
- Kafka Enabled: Yes or No.
- Syslog Forensics Enabled: Yes or No.
- Server Discovery: default, Server Discovery by Device. Click to open a new table.
- Syslog Forensics Flows: default, Syslog Forensics Flows. Click to open a new table.
- PENs: click to refresh.
- DNS cache: click to delete.
- Users seen.
- Users seen to IP address.
- Event codes.
- Ext codes.
- App IDs.
- De-duplication codes.
- Syn sources reports.
- Syn destinations reports.
- Loaded Netflow archives.
- Netflow tables.
- Oldest Netflow data.
- Oldest Netflow device.
- Oldest Netflow realtime.
- FlowSec tables.
- Oldest flowsec data.
- Oldest event summary.
- MB per day for forensics.
- MB per day for flowsec.
- Cloud Servers
- SNMP Stats
- Device IP - the IP address of the SNMP device.
- Device Name - the name of the SNMP device.
- Key - the internal identifier of the request source.
- Size - the number of rows returned in this request.
- When the value 0 is returned it means that the SNMP query was successful, but the table returned was empty. This value is related to the Empty Response OID(s) table.
- When the value -1 is returned it means that the request for that entry failed.This value is related to the No Response OID(s) table.
- Start - the start time of the last SNMP request.
- Duration - the last request duration (in milliseconds).
- Uses - the number of this type of requests made.
- Total Duration - The total amount of time (in milliseconds) it took for all the requests of this type.
- Average - the average duration across all requests (in milliseconds).
- Max Duration - the duration of the longest request of this type (in milliseconds).
- Max Time - the timestamp of the maximum duration across all requests.
- Largest tables all forensics by device: click to open new table.
On the related row, click the

On this page you find the list of servers that GigaFlow discovered from previous VPC flow records. This list is used to identify servers when there are no other methods to determine the server side of the conversation (either source or destination).
On the related row, click the

On this page you can find all the statistics for the SNMP requests sent by all your SNMP devices. The columns of this table have the following descriptions:
DB Connections
This page displays the performance of database connections. The database start time and uptime are displayed prominently at the top of the page.
The DB connections table lists the most recent database connections. See PostgreSQL documentation for more.
Select how many entries to view from the drop-down menu, i.e. the 10, 50, 100 or All. The default selection is 50.
The table lists:
- Database name.
- Client.
- Start time.
- Duration of connection.
- Waiting.
- Process ID.
- Query.
- Action, i.e. Remove.
DB Locks
You can view any PostgreSQL database deadlocks to help with troubleshooting performance problems. See PostgreSQL documentation for more. The table lists:
- The name of database involved.
- The relation involved. This is an internal PostgreSQL object identifier.
- The ID of the transaction targeted by the lock, or null if the target is not a transaction ID.
- The name of the lock mode held or desired by this process.
- If the lock was granted or not: this is true if the lock is held, false if the lock is awaited.
- The user that initiated the transaction.
- The query involved in the transaction.
- The start time of the transaction.
- The age of the transaction.
- The process ID of the server process holding or awaiting this lock, or null if the lock is held by a prepared transaction.
Named Tables
This page displays named table performance. The start time and uptime are displayed prominently at the top of the page. See PostgreSQL documentation for more.
Select how many entries to view from the drop-down menu, i.e. the 10, 50, 100 or All. The default selection is 10. You can also search for specific tables.
Prepared Tables
This page displays prepared table performance. The start time and uptime are displayed prominently at the top of the page. See PostgreSQL documentation for more.
Select how many entries to view from the drop-down menu, i.e. the 10, 50, 100 or All. The default selection is 10. You can also search for specific tables.
Users
Located at System > Users.
New Add links along top of page.
Here you can view and edit information for all GigaFlow users and user groups. There are three categories of user on GigaFlow:
- Local users; these are users set up for the particular GigaFlow installation.
- LDAP users; these are network users authenticated by LDAP.
- Portal users; these are users identified by a username and IP address. Portal user access is useful for programmatic access to the system, i.e. scripts.
Existing Users
Select how many entries to view from the drop-down menu, i.e. the 10, 50, 100 or All. The default selection is 10. You can also search for specific usernames or IDs using the search box.
All users are listed here. Information displayed includes:
- Name.
- Login ID.
- User type. Local users exist in the local database only. LDAP users were entered locally but authenticated against the LDAP server.
- User specific settings.
- User password.
- Actions, i.e Remove user, Edit user or Change Password.
Add Local User
To add a new local user:
- Enter the email address of the new user. This is the same as the login name.
- Enter a display name for the new user.
- Select a user role from the drop-down menu, e.g. normal or administrator.
- Enter a password for the new user.
- Click Add User to add the new user.
Add User Group
To add a new user group:
- Enter the new user group name.
- Select abilities to associate with the new user group.
- Click Add User Group to add the new user group.
Existing User Groups
This table lists all existing user groups along with associated abilities.
For each user group:
- Click the small x beside an ability to remove it.
- Select new abilities from the drop-down menu to the right and click Add to add abilities to a user group.
Existing LDAP Groups
Information displayed includes:
- Name.
- Settings.
- Actions, e.g. Edit user or Remove user.
Add LDAP User
Enter the domain name and ID of the user you want to allow to log into the system. They will be added as normal users.
To add a new LDAP user:
- Enter the new user ID.
- Enter the new user domain.
- Click Add LDAP User.
Add LDAP Group
To add a new LDAP user group:
- Select a group from the drop-down menu.
- You can also apply a filter to limit number of available groups. Enter filter text and click Apply LDAP Filter. (You can use *filter text* for wild card searches.)
- Select user role, e.g. normal or administrator.
- Click Add LDAP Group to add the new LDAP group.
Existing LDAP Nested Groups
Information displayed includes:
- Name.
- Settings.
- Actions, e.g. Edit user or Remove user.
Existing Portal Users
- Select how many entries to view from the drop-down menu, i.e. the 10, 50, 100 or All. The default selection is 10. You can also search for specific usernames or IDs using the search box.
Information displayed includes:
- Login ID.
- IP address.
- User name.
- Actions, e.g. Edit user or Remove user.
Add Portal User
To add a new portal user:
- Enter the new IP regular expression.
- Enter the new user regular expression.
- Click Add Portal User.
Existing Data Access Groups
This table lists all of the currently configured Data Access Groups.
For each Data Access Group:
- You can see the number of sites allowed under the entries column.
- Remove the site
- Click Edit to Edit the group.
Add Data Access Group
This function allows you to apply a filter to the data a user requests automatically. These filters are based on Sites and a user can have access to many Sites using this feature.
To add a new Data Access Group:
- Enter a unique name for this group.
- Enter a description for this Data Access Group
- Click Add Access Group to add the new Access group.
Once added, you can edit the group to control which Sites are assigned to it, in the Users own settings you can then assign them to any available Data Access Group.
Watchlists
Located at System > Watchlists.
GigaFlow uses a blacklist compiled from multiple online sources. These lists are retrieved every hour and merged into a list of about 30,000 potentially dangerous IP addresses. Your GigaFlow system checks this hourly-updated list every five minutes and updates the local list when necessary.
Terminology
We are reviewing our code watchlist terminology and will update this documentation to reflect any changes.
Blacklists Available
This table lists the online blacklists available with relevant information. Information includes:
- The source URL of the blacklist.
- The size, in number of entries, of this blacklist.
- Confidence level assigned to this blacklist, i.e. your confidence in its completeness and accuracy.
- Severity or importance assigned to this blacklist.
- The date and time of the last update.
- The provider of the blacklist, defaulting to Gigaflow.
- The number of entries.
- The total number of events related to each blacklist.
- You can unsubsribe from any blacklist.
New Blacklist Source
To add a new blacklist source:
- Click the Add Whitelist Source icon, first from left at the top of the page.
- Enter the URL of the new blacklist.
- Enter a display name for the new blacklist.
- Enter the importance (or severity) of the new blacklist.
- Enter your confidence in the new blacklist, i.e. your confidence in its completeness and accuracy.
- Enter a refresh rate in minutes (defaults to 1 minute).
- Click Subscribe to add the new blacklist source.
Blacklist Actions
- Click the Blacklist Actions icon, last from left at the top of the page.
To refresh blacklists automatically, select Yes.
Whitelist Items
GigaFlow can alert on flow entries that match known bad IP addresses, scanning or outside profiles. Whitelisting provides the facility to tell the checking mechanism in GigaFlow that particular IPs or subnets should not raise an exception on any of the defined conditions. When defining a whitelist you should specify a reason for excluding a host or hosts. If you set the IP address to that of the infrastructure device and the mask to zero, GigaFlow will whitelist all traffic for the device.
The whitelist table shows a list of the current whitelisted items, including the following information:
- Address.
- Mask.
- Entered.
- User.
- Reason.
- Hits, i.e. the number of matched flows to that item.
- Action.
You can select the number of items to show from the dropdown menu above the table; the default is 50 items.
To add a new whitelist entry:
- Click the Add Whitelist Entry icon, second from left at the top of the page.
- Enter IP address of whitelisted site.
- Enter its IP mask.
- Enter a reason for its whitelisting.
- Click Add.
Locally Defined Blacklists
The locally defined blacklist table shows a list of the existing locally-defined blacklists, including the following information:
- The source blacklist.
- The blacklist category.
- The size of the blacklist; this is the number of entries on the list.
- Your confidence in the black list, i.e. your confidence in its completeness and accuracy.
- The importance (or severity) of the blacklist.
- The provider of the blacklist.
- Entries.
- Action.
To add a new local blacklist:
- Click the Add Local Blacklist icon, third from left at the top of the page.
- Enter a category, or name, for the blacklist.
- Enter the importance (or severity) of the new local blacklist.
- Enter your confidence in the new local blacklist, i.e. your confidence in its completeness and accuracy.
- Click Subscribe to add the new local blacklist.
- After submitting the local blacklist, enter IP addresses, separated by a comma or on a new line in the Entries text area and click Save.
Proxies
Adding a noproxy=true flag to a watchlist URL allows the system to bypass proxy servers and access the list directly, i.e.
{URL to file}?NOPROXY=true
Appendices
Forensic Report Types
See Configuration > Reporting for instructions on how to configure and create new report types.
The different types of pre-loaded report are listed here. Refer to the Direct Filtering Syntax table above. Queries are performed on the PostgreSQL using SQL.
The Application Flows report is commonly used.
When this report is run for an infrastructure device on your network, GigaFlow returns the following information for each application flow associated with the device:
- A source address.
- A destination address.
- The application involved.
- A graph of the volume of data transmitted.
The different report types are:
Application
- The report name.
- The associated table query, in this case:
select srcadd as srcadd,dstadd as dstadd,appid as appid, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcadd,dstadd,appid ORDERBY LIMITROW
- The table value field, in this case:
bits_total
- The graph query, in this case:
select FIRSTSEEN as afirstseen,srcadd as srcadd,dstadd as dstadd,appid as appid, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcadd,dstadd,appid order by srcadd,dstadd,appid,afirstseen
- The graph time field, in this case:
afirstseen
- The graph value field, in this case:
bits_avgsec
- The graph key field(s), separated by "__", in this case:
srcadd__dstadd__appid
ASs by Dst
Table Query: select srcadd as srcadd,dstadd as dstadd,appid as appid, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcadd,dstadd,appid ORDERBY LIMITROW
Table Value Field:
Graph Query: select FIRSTSEEN as afirstseen,srcadd as srcadd,dstadd as dstadd,appid as appid, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcadd,dstadd,appid order by srcadd,dstadd,appid,afirstseen
Graph Time Field:
Graph Value Field:
Graph Key Field(s) separated by __: srcas
ASs by Source
Table Query: select srcas as srcas, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcas ORDERBY LIMITROW
Table Value Field:
Graph Query: select FIRSTSEEN as afirstseen,srcas as srcas, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcas order by srcas,afirstseen
Graph Time Field:
Graph Value Field:
Graph Key Field(s) separated by __:
ASs Pairs
Table Query: select srcas as srcas,dstas as dstas, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcas,dstas ORDERBY LIMITROW
Table Value Field:
Graph Query: select FIRSTSEEN as afirstseen,srcas as srcas,dstas as dstas, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcas,dstas order by srcas,dstas,afirstseen
Graph Time Field:
Graph Value Field:
Graph Key Field(s) separated by __:
srcas__dstas
Address Pairs
Table Value Field: bits_total
Graph Query: select FIRSTSEEN as afirstseen,srcadd as srcadd,dstadd as dstadd, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcadd,dstadd order by srcadd,dstadd,afirstseen
Graph Time Field: afirstseen
Graph Value Field: bits_avgsec
Graph Key Field(s) separated by __: srcadd__dstport
Addresses As Sources And Dest Port By Dest Count (Edit?)
Table Query: select srcadd,dstport,count(distinct(dstadd)) as dstcount from netflow WHERECLAUSE group by srcadd,dstport ORDERBY LIMITROW
Table Value Field: dstcount
Graph Query: select FIRSTSEEN as afirstseen, srcadd,dstport,cast((count(distinct(dstadd))) as bigint) as dstcount from netflow WHERECLAUSE group by afirstseen,srcadd,dstport order by srcadd,dstport,dstcount,afirstseen asc
Graph Time Field: afirstseen
Graph Value Field: dstcount
Graph Key Field(s) separated by __:
Addresses By Dest
Table Query: select dstadd as dstadd, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by dstadd ORDERBY LIMITROW
Table Value Field: bits_total
Graph Query: select FIRSTSEEN as afirstseen,dstadd as dstadd, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,dstadd order by dstadd,afirstseen
Graph Time Field: afirstseen
Graph Value Field: bits_avgsec
Graph Key Field(s) separated by __:dstadd
Addresses By Source
Table Query:
select srcadd as srcadd, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcadd ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,srcadd as srcadd, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcadd order by srcadd,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
srcadd
All Fields
Table Query:
select firstseen,duration,device,customerid as tgsrc,engineid as tgdst,userid,userdomain,srcadd,dstadd,srcport,dstport,appid,postureid,nexthop,srcmac,dstmac,device||'_'||inif as difin,device||'_'||outif as difout,pkts,bytes*8 as bits,flags,proto,tos,srcas,dstas,spare as fpr,url,fwextcode,fwevent from netflow WHERECLAUSE ORDERBY LIMITROW
Table Value Field:
firstseen
Graph Query:
select FIRSTSEEN as afirstseen, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen order by afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
All Fields Avg FPR
Table Query:
select firstseen,duration,cast( spare as integer) as fpr,device,customerid as tgsrc,engineid as tgdst,srcadd,dstadd,srcport,dstport,appid,nexthop,srcmac,dstmac,inif,outif,pkts,bytes*8 as bits,flags,proto,tos,srcas,dstas from netflow WHERECLAUSE and spare>0 ORDERBY LIMITROW
Table Value Field:
firstseen
Graph Query:
select FIRSTSEEN as afirstseen,cast( avg(spare) as integer) as maxfpr from netflow WHERECLAUSE and spare >0 group by afirstseen order by afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
maxfpr
Graph Key Field(s) separated by __:
All Fields Max FPR
Table Query:
select firstseen,duration,cast( spare as integer) as fpr,device,customerid as tgsrc,engineid as tgdst,srcadd,dstadd,srcport,dstport,appid,nexthop,srcmac,dstmac,inif,outif,pkts,bytes*8 as bits,flags,proto,tos,srcas,dstas from netflow WHERECLAUSE and spare>0 ORDERBY LIMITROW
Table Value Field:
firstseen
Graph Query:
select FIRSTSEEN as afirstseen,cast( max(spare) as integer) as maxfpr from netflow WHERECLAUSE and spare >0 group by afirstseen order by afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
maxfpr
Graph Key Field(s) separated by __:
Application Flows
Table Query:
select srcadd as srcadd,dstadd as dstadd,appid as appid, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcadd,dstadd,appid ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,srcadd as srcadd,dstadd as dstadd,appid as appid, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcadd,dstadd,appid order by srcadd,dstadd,appid,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
srcadd__dstadd__appid
Application Flows With User
Table Query:
select srcadd as srcadd,dstadd as dstadd,appid as appid,userid as userid, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcadd,dstadd,appid,userid ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,srcadd as srcadd,dstadd as dstadd,appid as appid,userid as userid, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcadd,dstadd,appid,userid order by srcadd,dstadd,appid,userid,afirstseen asc
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __: srcadd__dstadd__appid__userid
Applications With Flow Count
Table Query:
select appid ,count(*) as flowcount, count(distinct(srcadd)) as srccount, count(distinct(dstadd)) as dstcount, cast(sum(bytes*8)as bigint) as bits_total from netflow WHERECLAUSE group by appid ORDERBY LIMITROW
Table Value Field:
flowcount
Graph Query:
select FIRSTSEEN as afirstseen,appid ,count(*) as flowcount from netflow WHERECLAUSE group by afirstseen,appid order by flowcount,afirstseen asc
Graph Time Field:
afirstseen
Graph Value Field:
flowcount
Graph Key Field(s) separated by __:
appid
Class Of Service
Table Query:
select tos as tos, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by tos ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,tos as tos, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,tos order by tos,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
tos
Duration Avg
Table Query:
select firstseen,duration,cast( spare as integer) as fpr,device,customerid as tgsrc,engineid as tgdst,srcadd,dstadd,srcport,dstport,appid,nexthop,srcmac,dstmac,inif,outif,pkts,bytes*8 as bits,flags,proto,tos,srcas,dstas from netflow WHERECLAUSE ORDERBY LIMITROW
Table Value Field:
duration
Graph Query:
select FIRSTSEEN as afirstseen,cast( avg(duration) as bigint) as avgduration from netflow WHERECLAUSE group by afirstseen order by afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
avgduration
Graph Key Field(s) separated by __:
Duration Max
Table Query:
select firstseen,duration,cast( spare as integer) as fpr,device,customerid as tgsrc,engineid as tgdst,srcadd,dstadd,srcport,dstport,appid,nexthop,srcmac,dstmac,inif,outif,pkts,bytes*8 as bits,flags,proto,tos,srcas,dstas from netflow WHERECLAUSE ORDERBY LIMITROW
Table Value Field:
duration
Graph Query:
select FIRSTSEEN as afirstseen,cast( max(duration) as bigint) as maxduration from netflow WHERECLAUSE group by afirstseen order by afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
maxduration
Graph Key Field(s) separated by __:
FW Event
Table Query:
select fwevent as fwevent, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by fwevent ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,fwevent as fwevent, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,fwevent order by fwevent,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
fwevent
FW Ext Code
Table Query:
select fwextcode as fwextcode, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by fwextcode ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,fwextcode as fwextcode, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,fwextcode order by fwextcode,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
fwextcode
Interface Pairs
Table Query:
select device as device,device||'_'||inif as difin,device||'_'||outif as difout, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by device,difin,difout ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,device as device,device||'_'||inif as difin,device||'_'||outif as difout, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,device,difin,difout order by device,difin,difout,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
device__difin__difout
Interface By Dest
Table Query:
select device as device,device||'_'||outif as difout, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by device,difout ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,device as device,device||'_'||outif as difout, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,device,difout order by device,difout,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
device__difout
Interfaces By Destination Pct
Table Query:
select netflow.device||'_'||outif as difout ,cast(sum((bytes)*8)/(REPORTPERIOD/1000) as bigint) as pct_avg_out from netflow WHERECLAUSE group by difout ORDERBY LIMITROW
Table Value Field:
pct_avg_out
Graph Query:
select FIRSTSEEN as afirstseen,device||'_'||outif as difout ,cast(sum((bytes)*8)/(MODER/1000) as bigint) as pct_avg_out from netflow WHERECLAUSE group by afirstseen,difout order by pct_avg_out,afirstseen asc
Graph Time Field:
afirstseen
Graph Value Field:
pct_avg_out
Graph Key Field(s) separated by __:
difout
Interfaces By Source
Table Query:
select device as device,device||'_'||inif as difin, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by device,difin ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,device as device,device||'_'||inif as difin, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,device,difin order by device,difin,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
device__difin
Interfaces By Source Pct
Table Query:
select device||'_'||inif as difin ,cast(sum((bytes)*8)/(REPORTPERIOD/1000) as bigint) as pct_avg_in from netflow WHERECLAUSE group by difin ORDERBY LIMITROW
Table Value Field:
pct_avg_in
Graph Query:
select FIRSTSEEN as afirstseen,device||'_'||inif as difin ,cast(sum((bytes)*8)/(MODER/1000) as bigint) as pct_avg_in from netflow WHERECLAUSE group by afirstseen,difin order by pct_avg_in,afirstseen asc
Graph Time Field:
afirstseen
Graph Value Field:
pct_avg_in
Graph Key Field(s) separated by __:
difin
MAC Address Pairs
Table Query:
select srcmac as srcmac,dstmac as dstmac, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcmac,dstmac ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,srcmac as srcmac,dstmac as dstmac, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcmac,dstmac order by srcmac,dstmac,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
srcmac__dstmac
MAC Addresses By Dest
Table Query:
select dstmac as dstmac, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by dstmac ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,dstmac as dstmac, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,dstmac order by dstmac,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
dstmac
MAC Addresses By Source
Table Query:
select srcmac as srcmac, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcmac ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,srcmac as srcmac, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcmac order by srcmac,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
srcmac
Ports As Dest By Dest Add Popularity
Table Query:
select dstport,count(distinct(dstadd)) as dstcount from netflow WHERECLAUSE group by dstport ORDERBY LIMITROW
Table Value Field:
dstcount
Graph Query:
select FIRSTSEEN as afirstseen, dstport,cast((count(distinct(dstadd))) as bigint) as dstcount from netflow WHERECLAUSE group by afirstseen,dstport order by dstport,dstcount,afirstseen asc
Graph Time Field:
afirstseen
Graph Value Field:
dstcount
Graph Key Field(s) separated by __:
dstport
Ports As Dest By Src Add Popularity
Table Query:
select dstport,count(distinct(srcadd)) as srccount from netflow WHERECLAUSE group by dstport ORDERBY LIMITROW
Table Value Field:
srccount
Graph Query:
select FIRSTSEEN as afirstseen, dstport,cast((count(distinct(srcadd))) as bigint) as srccount from netflow WHERECLAUSE group by afirstseen,dstport order by dstport,srccount,afirstseen asc
Graph Time Field:
afirstseen
Graph Value Field:
srccount
Graph Key Field(s) separated by __:
dstport
Ports As Src By Dest Add Popularity
Table Query:
select srcport,count(distinct(dstadd)) as dstcount from netflow WHERECLAUSE group by srcport ORDERBY LIMITROW
Table Value Field:
dstcount
Graph Query:
select FIRSTSEEN as afirstseen, srcport,cast((count(distinct(dstadd))) as bigint) as dstcount from netflow WHERECLAUSE group by afirstseen,srcport order by srcport,dstcount,afirstseen asc
Graph Time Field:
afirstseen
Graph Value Field:
dstcount
Graph Key Field(s) separated by __:
srcport
Ports As Src By Src Add Popularity
Table Query:
select srcport,count(distinct(srcadd)) as srccount from netflow WHERECLAUSE group by srcport ORDERBY LIMITROW
Table Value Field:
srccount
Graph Query:
select FIRSTSEEN as afirstseen, srcport,cast((count(distinct(srcadd))) as bigint) as srccount from netflow WHERECLAUSE group by afirstseen,srcport order by srcport,srccount,afirstseen asc
Graph Time Field:
afirstseen
Graph Value Field:
srccount
Graph Key Field(s) separated by __:
srcport
Ports By Dest
Table Query:
select dstport as dstport, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by dstport ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,dstport as dstport, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,dstport order by dstport,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
dstport
Ports By Source
Table Query:
select srcport as srcport, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcport ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,srcport as srcport, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcport order by srcport,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
srcport
Posture
Table Query:
select postureid as postureid, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by postureid ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,postureid as postureid, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,postureid order by postureid,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
postureid
Protocols
Table Query:
select proto as proto, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by proto ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,proto as proto, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,proto order by proto,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
proto
Servers As Dest With Ports
Table Query:
select dstadd ,dstport,srccount,localports,remoteports,sessions,(bytes*8) as bits from (select dstadd as dstadd,dstport,count(distinct(srcadd)) as srccount,count(distinct(dstport)) as localports,count(distinct(srcport)) as remoteports,count(*) as sessions,cast(sum((bytes)) as bigint) as bytes from netflow WHERECLAUSE group by dstadd,dstport ) as a where a.sessions>5 and a.localports<5 and a.srccount>5 group by dstadd,dstport,srccount,sessions,localports,remoteports,bytes ORDERBY LIMITROW
Table Value Field:
srccount
Graph Query:
select afirstseen ,dstadd ,dstport,srccount as srcsavgsec,localports,bits_avgsec from (select FIRSTSEEN as afirstseen,dstadd as dstadd ,dstport,count(distinct(srcadd)) as srccount,count(distinct(dstport)) as localports,count(distinct(srcport)) as remoteports,count(*) as records,cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,dstadd ,dstport) as a where a.records>5 and a.localports<3 and a.srccount>5 group by afirstseen,dstadd ,dstport,srccount,localports,bits_avgsec order by dstadd,afirstseen asc
Graph Time Field:
afirstseen
Graph Value Field:
srcsavgsec
Graph Key Field(s) separated by __:
dstadd__dstport
Servers As Dst Address
Table Query:
select dstadd ,srccount,localports,remoteports,sessions,(bytes*8) as bits from (select dstadd as dstadd,count(distinct(srcadd)) as srccount,count(distinct(dstport)) as localports,count(distinct(srcport)) as remoteports,count(*) as sessions,cast(sum((bytes)) as bigint) as bytes from netflow WHERECLAUSE group by dstadd ) as a where a.sessions>5 and a.localports<5 and a.srccount>5 group by dstadd,srccount,sessions,localports,remoteports,bytes ORDERBY LIMITROW
Table Value Field:
srccount
Graph Query:
select afirstseen ,dstadd ,srccount as srcsavgsec,localports,bits_avgsec from (select FIRSTSEEN as afirstseen,dstadd as dstadd,count(distinct(srcadd)) as srccount,count(distinct(dstport)) as localports,count(distinct(srcport)) as remoteports,count(*) as records,cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,dstadd) as a where a.records>5 and a.localports<5 and a.srccount>5 group by afirstseen,dstadd,srccount,localports,bits_avgsec order by dstadd,afirstseen asc
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
dstadd
Servers AS Src Address
Table Query:
select srcadd ,dstcount,localports,remoteports,sessions,(bytes*8) as bits from (select srcadd as srcadd,count(distinct(dstadd)) as dstcount,count(distinct(srcport)) as localports,count(distinct(dstport)) as remoteports,count(*) as sessions,cast(sum((bytes)) as bigint) as bytes from netflow WHERECLAUSE group by srcadd ) as a where a.sessions>5 and a.localports<5 and a.dstcount>5 group by srcadd,dstcount,sessions,localports,remoteports,bytes ORDERBY LIMITROW
Table Value Field:
dstcount
Graph Query:
select afirstseen ,srcadd ,dstcount as dstsavgsec,localports,bits_avgsec from (select FIRSTSEEN as afirstseen,srcadd as srcadd,count(distinct(dstadd)) as dstcount,count(distinct(srcport)) as localports,count(distinct(dstport)) as remoteports,count(*) as records,cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcadd) as a where a.records>5 and a.localports<5 and a.dstcount>5 group by afirstseen,srcadd,dstcount,localports,bits_avgsec order by srcadd,afirstseen asc
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
srcadd
Servers As Src With Ports
Table Query:
select srcadd ,srcport,dstcount,localports,remoteports,sessions,(bytes*8) as bits from (select srcadd as srcadd,srcport,count(distinct(dstadd)) as dstcount,count(distinct(srcport)) as localports,count(distinct(dstport)) as remoteports,count(*) as sessions,cast(sum((bytes)) as bigint) as bytes from netflow WHERECLAUSE group by srcadd,srcport ) as a where a.sessions>5 and a.localports<5 and a.dstcount>5 group by srcadd,srcport,dstcount,sessions,localports,remoteports,bytes ORDERBY LIMITROW
Table Value Field:
dstcount
Graph Query:
select afirstseen ,srcadd ,srcport,dstcount as dstsavgsec,localports,bits_avgsec from (select FIRSTSEEN as afirstseen,srcadd as srcadd ,srcport,count(distinct(dstadd)) as dstcount,count(distinct(srcport)) as localports,count(distinct(dstport)) as remoteports,count(*) as records,cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcadd ,srcport) as a where a.records>5 and a.localports<3 and a.dstcount>5 group by afirstseen,srcadd ,srcport,dstcount,localports,bits_avgsec order by srcadd,afirstseen asc
Graph Time Field:
afirstseen
Graph Value Field:
dstsavgsec
Graph Key Field(s) separated by __:
srcadd__srcport
Sessions
Table Query:
select srcadd as srcadd,srcport as srcport,dstadd as dstadd,dstport as dstport,appid as appid, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcadd,srcport,dstadd,dstport,appid ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,srcadd as srcadd,srcport as srcport,dstadd as dstadd,dstport as dstport,appid as appid, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcadd,srcport,dstadd,dstport,appid order by srcadd,srcport,dstadd,dstport,appid,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
srcadd__srcport__dstadd__dstport__appid
Sessions Flows
Table Query:
select firstseen as firstseen,srcadd as srcadd,srcport as srcport,dstadd as dstadd,dstport as dstport,appid as appid,proto as proto, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by firstseen,srcadd,srcport,dstadd,dstport,appid,proto ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,firstseen as firstseen,srcadd as srcadd,srcport as srcport,dstadd as dstadd,dstport as dstport,appid as appid,proto as proto, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,firstseen,srcadd,srcport,dstadd,dstport,appid,proto order by firstseen,srcadd,srcport,dstadd,dstport,appid,proto,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
firstseen__srcadd__srcport__dstadd__dstport__appid__proto
Sessions With Ints
Table Query:
select srcadd as srcadd,srcport as srcport,inif as inif,dstadd as dstadd,dstport as dstport,outif as outif,appid as appid, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcadd,srcport,inif,dstadd,dstport,outif,appid ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,srcadd as srcadd,srcport as srcport,inif as inif,dstadd as dstadd,dstport as dstport,outif as outif,appid as appid, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcadd,srcport,inif,dstadd,dstport,outif,appid order by srcadd,srcport,inif,dstadd,dstport,outif,appid,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
srcadd__srcport__inif__dstadd__dstport__outif__appid
Subnet Class A By Dest
Table Query:
select dstadd-modulus(dstadd,16777216) as dstsubneta, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by dstsubneta ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,dstadd-modulus(dstadd,16777216) as dstsubneta, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,dstsubneta order by dstsubneta,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
dstsubneta
Subnet Class A By Source
Table Query:
select srcadd-modulus(srcadd,16777216) as srcsubneta, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcsubneta ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,srcadd-modulus(srcadd,16777216) as srcsubneta, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcsubneta order by srcsubneta,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
srcsubneta
Subnet Class B By Dest
Table Query:
select dstadd-modulus(dstadd,65536) as dstsubnetb, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by dstsubnetb ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,dstadd-modulus(dstadd,65536) as dstsubnetb, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,dstsubnetb order by dstsubnetb,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
dstsubnetb
Subnet Class B By Source
Table Query:
select srcadd-modulus(srcadd,65536) as srcsubnetb, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcsubnetb ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,srcadd-modulus(srcadd,65536) as srcsubnetb, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcsubnetb order by srcsubnetb,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
srcsubnetb
Subnet Class C By Dest
Subnet Class C By Dest
Table Query:
select dstadd-modulus(dstadd,256) as dstsubnetc, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by dstsubnetc ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,dstadd-modulus(dstadd,256) as dstsubnetc, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,dstsubnetc order by dstsubnetc,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
dstsubnetc
Subnet Class C By Source
Subnet Class C By Source
Table Query:
select srcadd-modulus(srcadd,256) as srcsubnetc, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by srcsubnetc ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,srcadd-modulus(srcadd,256) as srcsubnetc, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,srcsubnetc order by srcsubnetc,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
srcsubnetc
Subnet Class C Destination By Dest IP Count
Table Query:
select dstadd-modulus(dstadd,256) as dstsubnetc,count(distinct(dstadd)) as dstcount from netflow WHERECLAUSE group by dstsubnetc ORDERBY LIMITROW
Table Value Field:
dstcount
Graph Query:
select FIRSTSEEN as afirstseen, dstadd-modulus(dstadd,256) as dstsubnetc,cast((count(distinct(dstadd))) as bigint) as dstcount from netflow WHERECLAUSE group by afirstseen,dstsubnetc order by dstcount,afirstseen asc
Graph Time Field:
afirstseen
Graph Value Field:
dstcount
Graph Key Field(s) separated by __:
dstsubnetc
Subnet Class C Source By Source IP Count
Table Query:
select srcadd-modulus(srcadd,256) as srcsubnetc,count(distinct(srcadd)) as srccount from netflow WHERECLAUSE group by srcsubnetc ORDERBY LIMITROW
Table Value Field:
srccount
Graph Query:
select FIRSTSEEN as afirstseen, srcadd-modulus(srcadd,256) as srcsubnetc,cast((count(distinct(srcadd))) as bigint) as srccount from netflow WHERECLAUSE group by afirstseen,srcsubnetc order by srccount,afirstseen asc
Graph Time Field:
afirstseen
Graph Value Field:
srccount
Graph Key Field(s) separated by __:
srcsubnetc
TCP Flags
Table Query:
select flags as flags, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by flags ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,flags as flags, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,flags order by flags,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
flags
Site By Dest
Table Query:
select engineid as tgdst, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by tgdst ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,engineid as tgdst, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,tgdst order by tgdst,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
tgdst
Site By Source
Table Query:
select customerid as customerid, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by customerid ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,customerid as customerid, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,customerid order by customerid,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
customerid
Clone Name:
Site Pairs
Table Query:
select customerid as tgsrc,engineid as tgdst, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by tgsrc,tgdst ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,customerid as tgsrc,engineid as tgdst, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,tgsrc,tgdst order by tgsrc,tgdst,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
tgsrc__tgdst
URLs
Table Query:
select url as url, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by url ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,url as url, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,url order by url,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
url
USers (Report)
Table Query:
select userid as userid, cast((sum(bytes)*8) as bigint) as bits_total from netflow WHERECLAUSE group by userid ORDERBY LIMITROW
Table Value Field:
bits_total
Graph Query:
select FIRSTSEEN as afirstseen,userid as userid, cast(sum((bytes)*8)/(MODER/1000) as bigint) as bits_avgsec from netflow WHERECLAUSE group by afirstseen,userid order by userid,afirstseen
Graph Time Field:
afirstseen
Graph Value Field:
bits_avgsec
Graph Key Field(s) separated by __:
userid
TCP Flags
|
0 ........
|
|
|
|
|
|